


Bit by Bit: Why Variable Sizes Shape Your Code
A Bit-Level Analysis of Type Specificity and Its Impact on Memory Allocation, CPU Register Utilization, and Runtime Performance in Systems Programming

When you're writing code, particularly if you've spent most of your time in higher-level languages like JavaScript or Python, it's easy to take variable sizes for granted. After all, in these languages, you just declare a variable and use it—no need to worry about how much memory it consumes or what specific type of number it represents.
But if you're getting into systems programming with languages like Rust or C, or if you're trying to optimize performance in any language, understanding variable sizes becomes crucial. It's not just about saving memory—it's about correctness, performance, and even security.
Moving from Scripting to Systems Programming
Many developers are making the transition from JavaScript to languages like Rust these days. It's a significant shift that introduces you to a world of unfamiliar concepts: the stack, the heap, pointers, system calls, and of course, fixed-size types.
The first roadblock many encounter? You can't just declare variables without specifying their type.
// In JavaScript
let age = 25;
// In Rust
let age: u8 = 25; // An unsigned 8-bit integerThat u8 isn't there to make your code look more complex—it serves critical purposes that affect how your program runs, how much memory it uses, and even whether it contains subtle bugs.
Why Types Have Fixed Sizes
At the most fundamental level, computers represent all information as sequences of bits—just zeros and ones. The way these bits are interpreted depends entirely on how many bits we're looking at and what rules we apply to interpret them.

With two bits, we can represent exactly four unique values: 00, 01, 10, and 11. If we're using these to represent unsigned integers, they correspond to 0, 1, 2, and 3. Want to represent the number 4? You'll need at least three bits.
Every additional bit doubles the range of possible values. Eight bits (one byte) gives us 2^8 or 256 different possible values.
For convenience, computers typically work with groups of 8 bits (bytes). That's why you commonly see types that use 8, 16, 32, or 64 bits—these are all multiples of 8.
The Memory Footprint of Your Variables
Let's consider a practical example: representing a person's age.
If you declare an age variable in JavaScript:
let age = 25;Behind the scenes, JavaScript will allocate enough memory to store any possible number value—typically 64 bits (8 bytes). This is massive overkill for storing an age, which realistically won't exceed 120.
In Rust or C, you could be more precise:
let age: u8 = 25; // Only uses 1 byteAn unsigned 8-bit integer (u8) can represent values from 0 to 255—perfect for an age value and seven times more memory-efficient than using a 64-bit number.
"But modern computers have gigabytes of RAM," you might say. "Why worry about a few bytes?"
It's true that for a single variable, the difference is negligible. But what happens when you're storing thousands or millions of age values—perhaps in a database of users? Suddenly, those wasted bytes add up to megabytes or even gigabytes of unnecessary memory usage.
Type Safety: Preventing Bugs Before They Happen
There's another benefit to fixed-size types that goes beyond memory efficiency. By declaring a variable as a specific type, you're making assertions about what values it can hold. This helps catch bugs at compile time instead of runtime.
For instance, if an age is represented as an unsigned 8-bit integer (u8 in Rust), the compiler will reject any code that tries to assign a negative value to it. This prevents a whole class of logic errors before your program even runs.
In contrast, in JavaScript:
let age = 25;
age = -10; // Perfectly valid, but probably a logic errorThe language happily allows this, even though a negative age makes no sense in most contexts.
Predictable Operations
Another area where fixed-size types shine is in arithmetic operations. Consider this JavaScript code:
let result = 5 + 3.7;What will result be? An integer or a floating-point value? Will JavaScript round the floating-point value before performing the operation, or will it convert the integer to a float?
The answer is that JavaScript will convert the integer to a float and then perform the operation, resulting in a floating-point value (8.7). But that's not immediately obvious from the code itself—you need to know JavaScript's implicit type conversion rules.
In systems programming languages, you can't mix different numeric types without being explicit about it:
let a: i32 = 5; // 32-bit signed integer
let b: f32 = 3.7; // 32-bit floating point
// let result = a + b; // Error: cannot add `f32` to `i32`
// You must explicitly convert one type to another
let result = a as f32 + b; // OK, result is f32 (8.7)This explicitness makes the code's behavior more predictable and helps prevent subtle bugs.
The Hidden Cost of Dynamic Typing
In scripting languages like Python and JavaScript, variable types are determined at runtime. This convenience comes at a cost: performance.
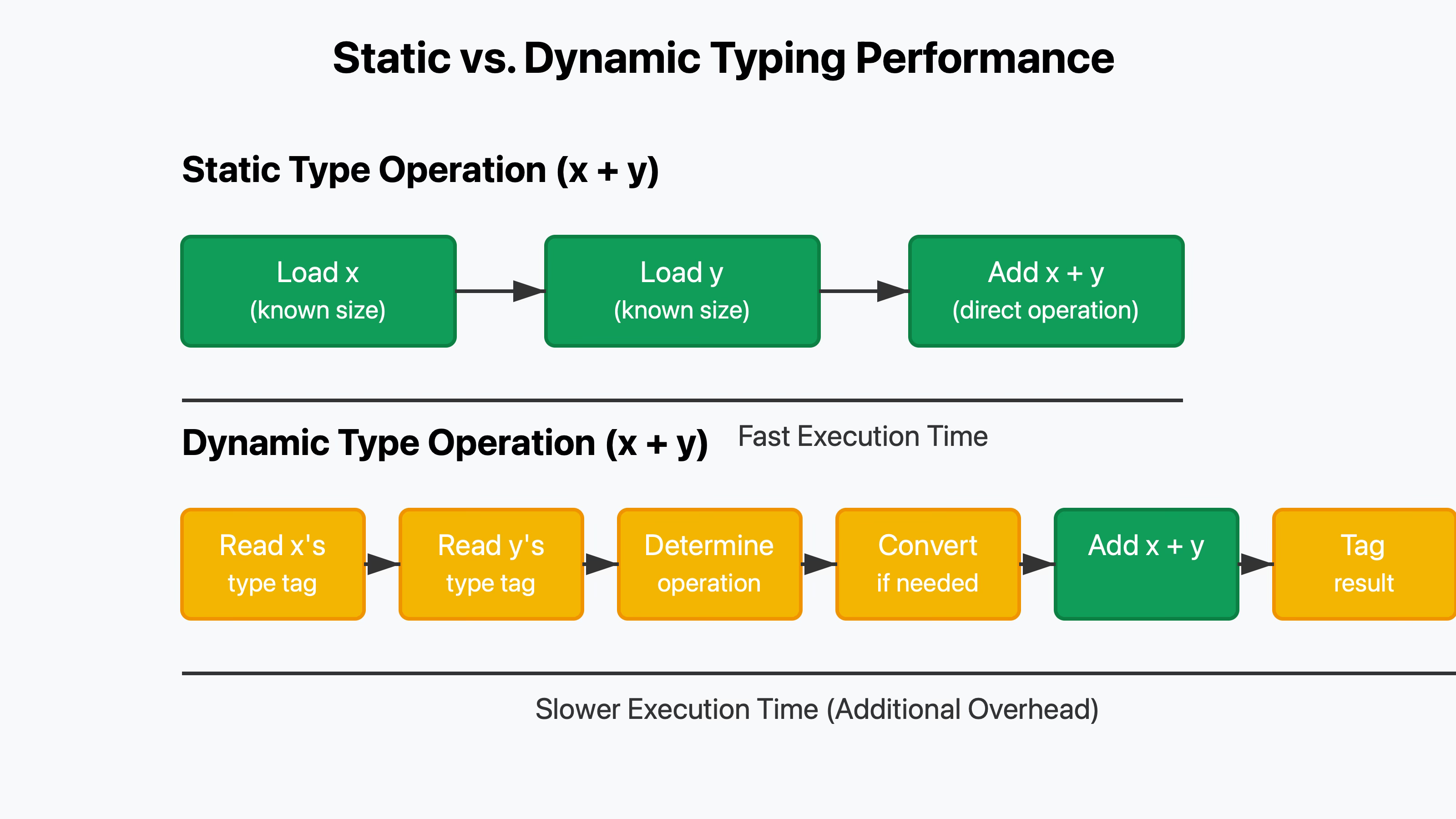
When you declare a variable in these languages, the interpreter not only allocates space for the value but also attaches type information (tags) to it. These tags tell the interpreter what kind of data the variable holds.
For example, when the interpreter sees:
let x = 5;
let y = "hello";
let z = x + y;It needs to:
Look at the type tag for
xand determine it's a numberLook at the type tag for
yand determine it's a stringDecide what operation to perform based on these types (in this case, convert
xto a string and concatenate)Create a new value with its own type tag
Each of these steps takes time. For simple operations like addition, the overhead of checking types can be many times greater than the actual operation itself.
Additionally, these type tags consume extra memory. A simple integer in Python might use 24 bytes or more of memory, when the actual value only needs a few bytes.
In contrast, when you use fixed-size types in a language like Rust:
let x: i32 = 5;
let y: i32 = 10;
let z = x + y;The compiler knows at compile time that x and y are 32-bit integers. It can emit machine code that directly:
Fetches both values from memory
Performs an integer addition
Stores the result
No type checking, no conversions, no extra memory usage—just the operation you asked for.
This is one of the main reasons why statically typed languages are typically orders of magnitude faster than dynamically typed ones for numeric computations.
Beyond Primitives: Composite Types and Dynamic Memory
The principles we've discussed don't just apply to simple values like integers and floats. They extend to composite types like arrays and structs.
In languages with fixed-size types, even complex data structures have sizes that are known at compile time. For example, a struct containing two 32-bit integers will always occupy exactly 8 bytes (plus any potential padding for alignment).
This presents a challenge when you need to work with data of varying sizes. For instance, what if you want an array that can grow or shrink dynamically?
The solution involves a special memory region called the heap, where data can be allocated dynamically. Instead of directly storing the array in your variable, you store a reference (or pointer) to that region of memory, plus metadata like the array's current size.
// Fixed-size array with known size at compile time
let fixed_array: [i32; 2] = [1, 2]; // Takes exactly 8 bytes
// Dynamically-sized vector that can grow and shrink
let mut dynamic_array: Vec<i32> = Vec::new(); // Initially empty
dynamic_array.push(1);
dynamic_array.push(2);
// Takes 24 bytes on the stack (for the Vec struct)
// plus however many bytes are needed on the heap for the actual dataThis approach allows for flexibility while still maintaining the performance benefits of fixed-size types for the individual elements.
Practical Examples: When Size Matters
Example 1: Embedded Systems
In embedded systems with limited memory, choosing appropriate variable sizes is crucial. Consider an Arduino Uno with only 2KB of RAM. If you're storing sensor readings:
// Each reading uses 4 bytes
int readings[100]; // Uses 400 bytes (20% of available RAM)
// Each reading uses only 1 byte
uint8_t readings[100]; // Uses 100 bytes (5% of available RAM)The difference is significant—using uint8_t instead of int allows you to store the same amount of data while using 75% less memory.
Example 2: Big Data Processing
When processing large datasets, the size of your variables directly impacts how much data you can handle at once. If you're analyzing millions of records and each record contains several fields, using appropriately sized types can mean the difference between processing the dataset in memory or having to resort to slower disk-based processing.
Example 3: Network Protocols
When designing network protocols, every byte counts. Using smaller variable sizes reduces bandwidth usage and speeds up communication. That's why many network protocols use fixed-size fields with precisely defined lengths.
Common Challenges and Solutions
Integer Overflow
One challenge with fixed-size types is the risk of overflow. If you try to store a value larger than the maximum value for a type, it will wrap around to the minimum value (for unsigned types) or produce undefined behavior (for signed types in some languages).
For example, with an 8-bit unsigned integer (range 0-255):
let mut x: u8 = 255;
x += 1; // Overflows to 0Solutions:
Choose types large enough for your expected values
Use checked arithmetic operations that return errors or options instead of silently overflowing
Validate inputs to ensure they're within the valid range for your types
Floating-Point Precision
Floating-point types come with their own set of challenges, particularly around precision. When working with floating-point values, you need to be aware that not all decimal numbers can be represented exactly.
let x: f32 = 0.1;
let y: f32 = 0.2;
let z = x + y;
println!("{}", z); // Might print 0.30000000000000004, not exactly 0.3Solutions:
Use fixed-point arithmetic for financial calculations
Consider the level of precision needed for your application and choose types accordingly
Be aware of precision issues when comparing floating-point values
Memory Alignment
Modern CPUs are designed to access memory most efficiently when data is aligned on certain boundaries. For example, a 32-bit value should ideally be stored at an address that's a multiple of 4 bytes.
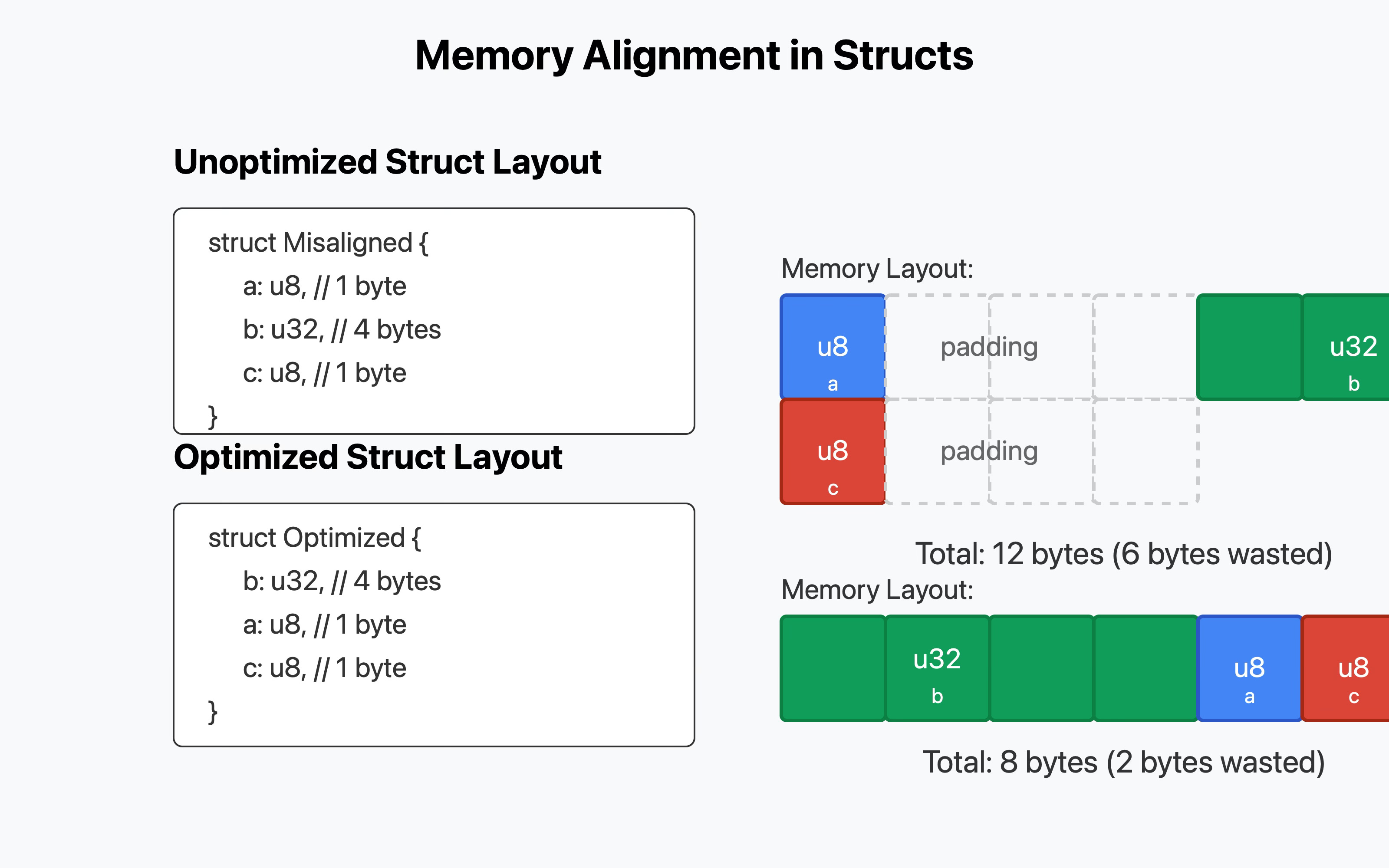
When defining structs, compilers often insert padding between fields to ensure proper alignment:
struct Misaligned {
a: u8, // 1 byte
// 3 bytes of padding inserted here
b: u32, // 4 bytes
c: u8, // 1 byte
// 3 bytes of padding inserted here
}
// Total size: 12 bytes (not 6 bytes!)Solutions:
Order struct fields from largest to smallest to minimize padding
Use special attributes or pragmas to control alignment when necessary
Be aware of alignment requirements when working with low-level memory operations
Performance Considerations
The size of your variables doesn't just affect memory usage—it can also impact performance in various ways.
Memory Access Patterns
Modern CPUs load data from memory in chunks (cache lines), typically 64 bytes at a time. If your data structures are too large or poorly organized, you might cause more cache misses, which slow down your program.
Using appropriately sized types and organizing data to maximize locality of reference can significantly improve performance.
CPU Register Usage
CPUs have registers of specific sizes (e.g., 64-bit registers on modern x86-64 processors). Operations that match the register size are often more efficient than those that don't.
However, smaller types can sometimes be more efficient if they allow more data to fit in cache at once.
SIMD Operations
Modern CPUs support SIMD (Single Instruction, Multiple Data) instructions that can operate on multiple values at once. The efficiency of these operations depends on how your data is organized and the sizes of your variables.
Conclusion: Choose Your Types Wisely
The size of your variables matters more than many programmers realize. It affects:
Memory usage
Performance
Correctness
Interoperability with other systems
Security (through preventing overflow and other vulnerabilities)
When writing software, especially in systems programming languages, it's worth taking the time to choose appropriate types for your data. Don't default to using the largest available type "just to be safe"—be intentional about your choices.
Remember that in programming, constraints often lead to better designs. By being conscious of the size and nature of your data, you'll write more efficient, correct, and maintainable code.
Exercises
Write a program that compares the memory usage of arrays of different integer types (e.g., 8-bit vs. 64-bit) with the same number of elements.
Implement a function that safely adds two integers of the same type, detecting and handling potential overflow.
Create a struct representing a person (with fields like name, age, and height) and experiment with the order of fields to see how it affects the total size of the struct.
Write a benchmark comparing the performance of operations on different-sized types (e.g., adding 8-bit integers vs. 64-bit integers).
Investigate how your programming language of choice represents different numeric types internally, and how much overhead is added by its type system.
By understanding the size of your variables and its implications, you'll be better equipped to write efficient, correct, and maintainable code, regardless of whether you're working in high-level scripting languages or low-level systems programming languages.
Some compilers will reorder fields in a type for memory packing/alignment purposes.