
Designing and Implementing Relational Databases: Bridging Theory and Primary Key Constraints in Database Design
Exploring the Intersection of Relational Algebra and Practical Key Management

Table of Contents
Introduction
The Theoretical Foundation
What is Relational Algebra?
Sets vs. Relations
Primary Keys in Relational Database Theory
Definition and Purpose
Primary Keys vs. Relational Algebra
Relational Algebra Operations and Schema Constraints
Union Operation
Intersection Operation
Difference Operation
Cartesian Product
Selection Operation
Projection Operation
Join Operations
Primary Key Preservation in Relational Operations
Key Preservation in Union
Key Preservation in Projection
Key Preservation in Joins
The Gap Between Theory and Practice
Theoretical Purity vs. Practical Implementation
How DBMSs Handle Key Constraints
Case Studies
Case Study 1: Union Operation and Key Constraints
Case Study 2: Join Operations and Primary Keys
Best Practices
Bridging Theory and Implementation
Preserving Semantic Integrity
Conclusion
Introduction
In database theory, there exists an interesting dichotomy: the elegant mathematical formalism of relational algebra often seems disconnected from the practical constraints like primary keys that database practitioners deal with daily. This article explores why relational algebra operations, particularly set operations like UNION, do not explicitly incorporate the concept of primary keys in their theoretical formulation, and what implications this has for database design and implementation.
When students first learn about relational algebra, they often wonder: "If primary keys are so fundamental to relational databases, why don't they feature prominently in relational algebra operations?" This question strikes at the heart of the distinction between the mathematical model and its practical application.
The Theoretical Foundation
What is Relational Algebra?
Relational algebra is a formal mathematical system developed by Edgar F. Codd in the early 1970s. It defines a set of operations on relations (tables) that form the theoretical foundation of relational database management systems. These operations include:
Set operations: UNION, INTERSECTION, DIFFERENCE
Specifically relational operations: SELECTION, PROJECTION, JOIN, DIVISION
Relational algebra focuses on manipulating sets of tuples (rows) without concern for how those tuples are physically stored or identified in an actual database. It deals with the logical structure rather than the physical implementation.
Sets vs. Relations
A critical distinction underlies the seeming disconnect between primary keys and relational algebra:
Mathematical sets do not contain duplicates by definition. In pure set theory, an element either belongs to a set or it doesn't; it cannot appear twice.
Relations in relational algebra are formally defined as sets of tuples. Following set theory principles, a relation cannot contain duplicate tuples.
In this theoretical context, there is no need for primary keys to identify unique tuples, because uniqueness is inherent in the definition of a set. Every tuple in a relation is already distinct from every other tuple.
Primary Keys in Relational Database Theory
Definition and Purpose
A primary key is a column or combination of columns that uniquely identifies each row in a table. In database implementation, primary keys serve several crucial purposes:
Ensuring data integrity by preventing duplicate rows
Providing an efficient means of accessing specific rows
Enabling relationships between tables through foreign keys
Supporting efficient indexing and query optimization
Primary Keys vs. Relational Algebra
Despite their importance in practical database systems, primary keys do not feature prominently in relational algebra for several reasons:
Mathematical purity: Relational algebra is based on set theory, where duplicates are implicitly forbidden.
Abstraction level: Relational algebra operates at a higher level of abstraction than physical database implementation.
Separation of concerns: The theory separates logical data operations from physical storage and access mechanisms.
This separation is intentional, allowing relational algebra to focus on the semantics of data manipulation without being tied to specific implementation details.
Relational Algebra Operations and Schema Constraints
Let's examine how various relational algebra operations interact with schema constraints like primary keys:
Union Operation
The UNION operation combines two relations that have the same schema (compatible attributes):
R ∪ S = {t | t ∈ R OR t ∈ S}
In pure relational algebra, duplicate tuples would be automatically eliminated because the result is a set. However, in SQL implementations, UNION also eliminates duplicates, while UNION ALL retains them.
-- Example:
-- Table Students1: {ID, Name, Department}
-- Table Students2: {ID, Name, Department}
-- UNION would automatically eliminate duplicates
-- based on all attributes, not just the primary key
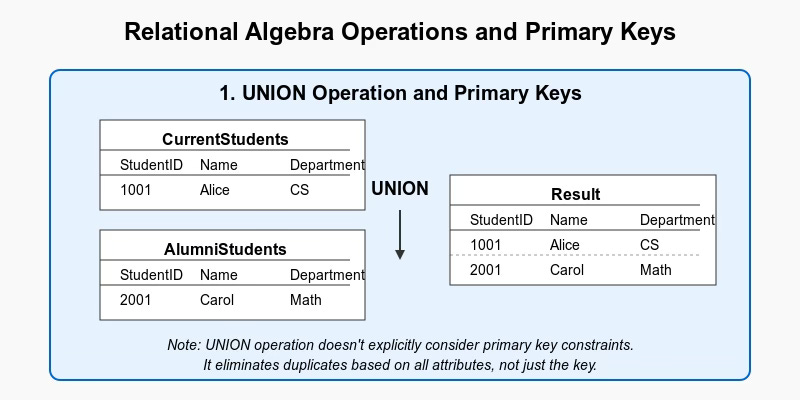
Key consideration: The primary key is not explicitly referenced in the operation itself. The uniqueness of tuples is ensured by the definition of sets, not by enforcing primary key constraints.
Intersection Operation
INTERSECTION returns tuples that appear in both relations:
R ∩ S = {t | t ∈ R AND t ∈ S}
Again, the operation makes no explicit reference to primary keys. Tuples are compared in their entirety.
Difference Operation
DIFFERENCE returns tuples that appear in the first relation but not in the second:
R - S = {t | t ∈ R AND t ∉ S}
Like other set operations, DIFFERENCE compares complete tuples without special treatment for primary key attributes.
Cartesian Product
The Cartesian product creates a new relation by combining each tuple from the first relation with each tuple from the second:
R × S = {(r, s) | r ∈ R AND s ∈ S}
The result typically has a combined schema that includes all attributes from both relations. This operation can create integrity issues since the combined tuples may not have a natural primary key.
Selection Operation
SELECTION filters tuples based on a predicate:
σₚ(R) = {t | t ∈ R AND p(t) is true}
Selection preserves the primary key of the original relation since it only filters rows without changing the schema.
Projection Operation
PROJECTION retains only specified attributes from a relation:
π₍ₐ₁,ₐ₂,...,ₐₙ₎(R) = {(t[a₁], t[a₂], ..., t[aₙ]) | t ∈ R}
This operation can potentially remove primary key attributes, leading to duplicate tuples in the result. In pure relational algebra, these duplicates would be eliminated, but this can result in data loss.
Join Operations
JOIN operations combine related tuples from two relations based on a join condition:
R ⋈ S = {(r, s) | r ∈ R AND s ∈ S AND θ(r, s) is true}
Natural joins and equijoins are particularly important for relating tables based on common attributes, which often involve primary key and foreign key relationships.
Primary Key Preservation in Relational Operations
While relational algebra doesn't explicitly incorporate primary keys, the preservation of keys through operations is an important consideration in database design.
Key Preservation in Union
When performing a UNION between two relations R and S:
If both R and S have the same primary key, the result maintains that primary key semantically.
However, the UNION operation itself doesn't verify this; it's the responsibility of the database designer or system to ensure integrity.
Consider two tables, CurrentStudents and AlumniStudents, both with primary key StudentID:
CurrentStudents:
StudentID | Name | Department
---------------------------------
1001 | Alice | Computer Science
1002 | Bob | Physics
AlumniStudents:
StudentID | Name | Department
---------------------------------
2001 | Carol | Mathematics
2002 | Dave | Biology
The UNION doesn't specifically check that StudentIDs are unique across both tables; it just eliminates duplicate rows.
Key Preservation in Projection
Projection can potentially destroy the uniqueness property of a primary key if any key attributes are removed:
Students:
StudentID | Name | Department | EnrollmentYear
----------------------------------------------
1001 | Alice | CS | 2022
1002 | Bob | Physics | 2021
1003 | Alice | Mathematics| 2023
π(Name, Department)(Students):
Name | Department
---------------------
Alice | CS
Bob | Physics
Alice | Mathematics
In this example, projecting only Name and Department creates a relation where rows are no longer uniquely identifiable by a primary key.
Key Preservation in Joins
Joins present complex key preservation issues:
Natural Join: May preserve keys from both relations if they're compatible
Theta Join: May require a compound key from both relations
Outer Joins: May introduce NULL values that complicate key constraints
The Gap Between Theory and Practice
Theoretical Purity vs. Practical Implementation
The gap between relational algebra's mathematical foundations and practical database systems explains why primary keys seem neglected in theoretical discussions:
Mathematical Sets vs. Database Tables: In set theory, uniqueness is implicit; in databases, it must be enforced.
Implementation Concerns: Physical storage, indexing, and access methods are abstracted away in the theory.
Extended Models: Many database systems implement an extended relational model that includes constraints, triggers, and other practical features not present in pure relational algebra.
How DBMSs Handle Key Constraints
Database management systems bridge the gap between theory and practice by implementing:
Constraint Mechanisms: PRIMARY KEY, UNIQUE, FOREIGN KEY declarations
Duplicate Handling: Different semantics for operations like UNION vs. UNION ALL
Integrity Enforcement: Preventing operations that would violate key constraints
-- Example of a constraint that goes beyond relational algebra
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
Name VARCHAR(100),
Department VARCHAR(50),
CONSTRAINT unique_name_dept UNIQUE (Name, Department)
);
Case Studies
Case Study 1: Union Operation and Key Constraints
Consider a university database with two relations:
OnCampusStudents:
StudentID | Name | Major | DormID
-------------------------------------
1001 | Alice | CS | D101
1002 | Bob | Physics | D205
1003 | Charlie | Math | D102
OffCampusStudents:
StudentID | Name | Major | Address
---------------------------------------
2001 | Diana | Chemistry | 123 Main St
2002 | Eve | Biology | 456 Oak Ave
1001 | Frank | English | 789 Pine Rd
When executing OnCampusStudents UNION OffCampusStudents, relational algebra treats the operation purely in terms of compatible tuples. The theoretical result would include all students, with no duplicates.
However, notice the problematic StudentID = 1001 appearing in both tables, but for different students (Alice and Frank). In a practical DBMS implementation:
The system might reject the operation if StudentID is defined as a primary key across the entire schema.
It might execute the operation but produce a result that violates the intended semantic constraint that StudentID uniquely identifies a student.
It might require additional data cleaning or transformation before the operation.
Case Study 2: Join Operations and Primary Keys
Consider a database with:
Orders:
OrderID | CustomerID | OrderDate
--------------------------------
1 | 101 | 2023-01-15
2 | 102 | 2023-01-16
3 | 101 | 2023-01-17
OrderItems:
OrderID | ProductID | Quantity
----------------------------
1 | P1 | 2
1 | P2 | 1
2 | P3 | 3
3 | P1 | 1
When joining these tables:
SELECT O.OrderID, O.CustomerID, OI.ProductID, OI.Quantity
FROM Orders O JOIN OrderItems OI ON O.OrderID = OI.OrderID;
The result has a compound primary key (OrderID, ProductID) that is not explicitly handled by relational algebra but is crucial for the semantic integrity of the result.
Best Practices
Bridging Theory and Implementation
To effectively bridge the gap between relational algebra and primary key management:
Understand the theoretical foundations of relational operations
Consider key preservation when designing database schemas and queries
Use integrity constraints appropriately in database implementations
Document key dependencies that may not be explicit in the schema
Preserving Semantic Integrity
When applying relational operations that might affect primary keys:
Pre-validate data before operations that could create duplicates
Use appropriate join types to maintain key relationships
Consider view designs that preserve key attributes
Add derived key columns when necessary for result relations
Conclusion
The apparent disconnect between relational algebra operations and primary key constraints reflects the intentional separation between mathematical formalism and practical implementation in database theory.
Pure relational algebra operates on relations as sets of tuples where uniqueness is implicit. It provides a clean, abstract model for data manipulation without being tied to specific implementation details like primary keys.
In contrast, practical database systems must bridge this gap by implementing constraint mechanisms that enforce integrity requirements, including primary key uniqueness. These systems extend the theoretical model to address the practical concerns of data management.
Understanding this distinction helps database designers and developers appreciate why texts on relational algebra may not emphasize primary keys, while still recognizing their critical importance in actual database implementations.
The art of good database design lies in applying theoretical principles while accommodating practical constraints—creating systems that are both mathematically sound and pragmatically effective.