
Improving PostgreSQL Snapshots Efficiency: Current Implementation, Challenges, and a Proposed Hybrid Design
Examine PostgreSQL's snapshot system, understand its performance limitations, and learn about a hybrid Commit Sequence Number (CSN) design that optimizes concurrency.

As PostgreSQL continues to evolve and face increasing demands from applications requiring both high concurrency and strong consistency guarantees, understanding the foundational mechanisms that enable these capabilities becomes crucial. Among these mechanisms, snapshots stand out as a core component of PostgreSQL's implementation of Multi-Version Concurrency Control (MVCC).
This article examines the current implementation of snapshots in PostgreSQL, identifies key challenges, and explores a promising hybrid design that could address these issues while paving the way for true distributed PostgreSQL deployments.
This article is very much inspired by the seminar of Ants Aasma (link here)
The Fundamentals of Database Concurrency
Before diving into PostgreSQL's specific implementation, it's worth revisiting why concurrency control matters and what problems it solves.
When multiple users interact with a database simultaneously, we need mechanisms to prevent them from interfering with each other's work. The famous ACID properties (Atomicity, Consistency, Isolation, Durability) provide a framework for thinking about these concerns:
Atomicity: Transactions are all-or-nothing—either all operations within a transaction complete, or none do
Consistency: The database transitions from one valid state to another
Isolation: Transactions operate as if they are the only ones running, despite concurrent execution
Durability: Once committed, transaction changes persist even through system failures
For this article, we're primarily concerned with Isolation, which allows developers to use a database without worrying about concurrent access. Without proper isolation, developers would face numerous challenges, such as:
Seeing inconsistent data as other transactions modify it mid-query
Being unable to update the database while long-running queries execute
Having difficulty verifying their own changes after committing them
PostgreSQL's approach to solving these problems is MVCC (Multi-Version Concurrency Control), and snapshots form a critical piece of this solution.
Snapshots in PostgreSQL's MVCC
A snapshot in PostgreSQL represents a point-in-time view of the database state. When a query starts, it acquires a snapshot that determines which versions of rows will be visible to it throughout its execution. This is fundamental to PostgreSQL's MVCC model—instead of locking rows, PostgreSQL maintains multiple versions of the same row, each tagged with transaction IDs that determine their visibility.
The key concept here is that when a transaction starts, it gets a deterministic rule to decide which row versions it can see. This rule remains constant throughout the transaction's lifetime, ensuring a consistent view of the database.
How PostgreSQL Implements Snapshots Today
When a transaction begins writing to the database, it acquires a transaction ID (XID). This is essentially a monotonically increasing counter managed in shared memory. Consider it like getting a ticket number at a service counter—each transaction gets the next number in sequence.
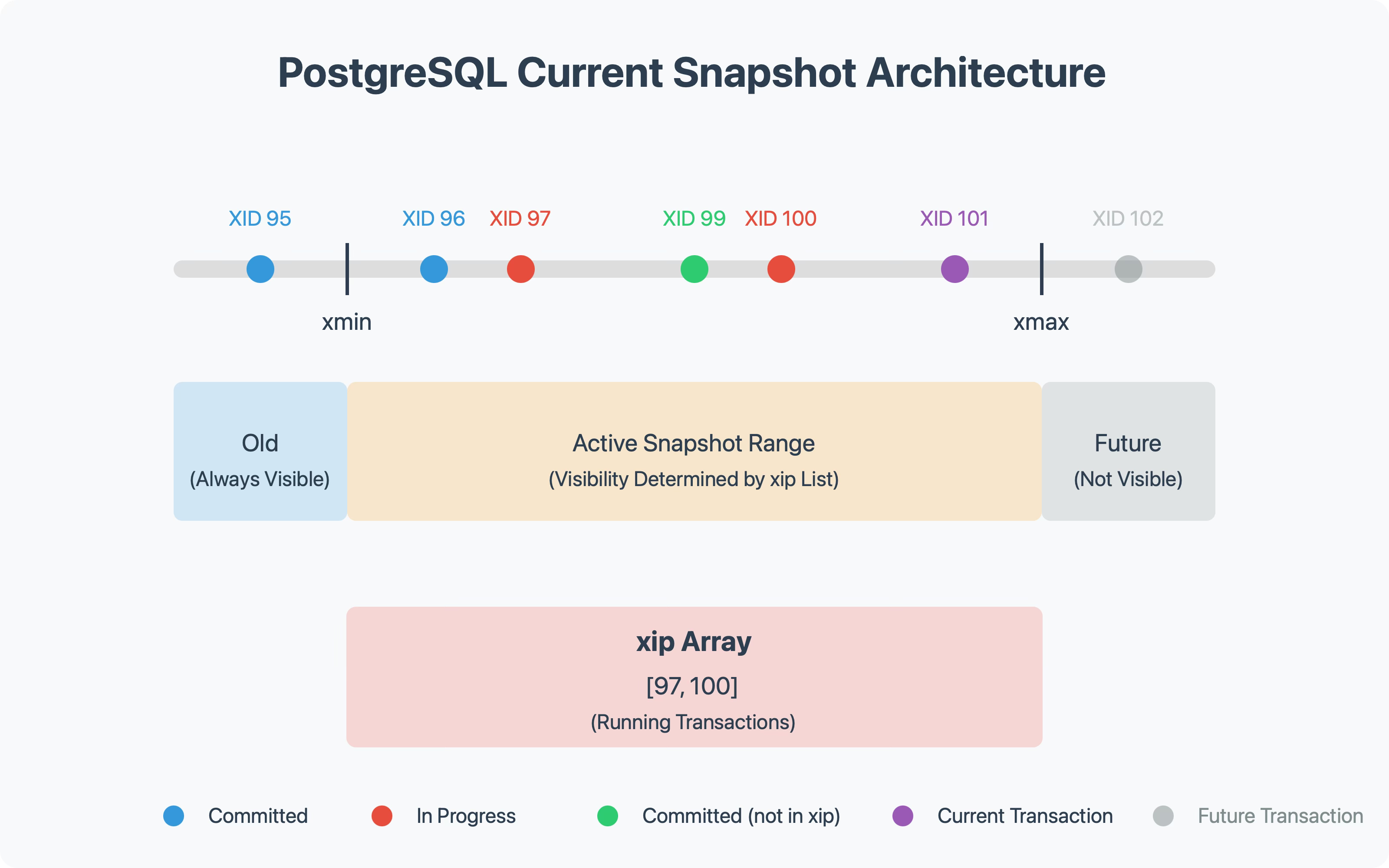
The crucial function for creating snapshots is GetSnapshotData(), which collects the following information:
xmax: The latest transaction ID that has completed (committed or aborted)
xmin: The smallest transaction ID that could still be running
xip: A list of all transaction IDs that are currently running
These three pieces of information allow PostgreSQL to categorize every row in the database from the perspective of the snapshot:
Transaction IDs smaller than xmin: These are "old" transactions that must have already completed
Transaction IDs greater than xmax: These are "future" transactions that started after the snapshot was taken
Transaction IDs in the xip list: These are "concurrent" transactions that were running when the snapshot was taken
Transaction IDs between xmin and xmax, but not in xip: These are transactions that must have completed before the snapshot was taken
For any row in the database, PostgreSQL can determine its visibility to a particular snapshot by examining the transaction ID associated with the row (stored in the row header) and applying these rules. If a transaction ID falls into the "old" or "completed" categories and is also marked as committed in the pg_xact commit log, the row is visible. Otherwise, it's invisible to that snapshot.
A Concrete Example
Let's break this down with a small example:
Transaction A starts and gets XID 100. It updates a row in the users table, changing a user's email.
Transaction B starts afterward and gets XID 101. It needs to read from the users table.
When Transaction B acquires its snapshot:
xmin might be 95 (the oldest running transaction)
xmax might be 101 (B's own XID)
xip would include 100 (A is still running) and 101 (B itself)
Now when B reads from the users table, it will see the old version of the row that A is updating, not the new version with the changed email. This is because the row's XID (100) is in the xip list, indicating a concurrent transaction that hasn't yet committed.
If A commits before B completes, B will still see the old version throughout its execution. This ensures a consistent view of the database, even as other transactions modify it.
Performance Improvements Over Time
This snapshot mechanism has been at the core of PostgreSQL for 26 years, but it hasn't remained static. Several optimizations have been implemented:
Lock-Free XID Publication
When a transaction begins, it needs to register its XID in shared memory. Originally, this required acquiring a lock. Now, transactions can publish their XIDs in a lock-free manner, writing directly to shared memory while ensuring proper memory ordering for visibility.
Group Commit
When many backends try to commit simultaneously, they can create a bottleneck on the ProcArray lock. With group commit, transactions queue up, and one committer updates the ProcArray for multiple transactions, significantly reducing contention.
PostgreSQL 14 Snapshot Improvements
PostgreSQL 14 introduced a major optimization where XIDs of running transactions are stored in a dense array, making scanning much faster. Additionally, snapshots are cached until the next commit, allowing reuse in read-heavy workloads.
These improvements have helped PostgreSQL scale to handle higher concurrency, but as we'll see, fundamental limitations remain.
Current Challenges with PostgreSQL Snapshots
Despite the optimizations, PostgreSQL's snapshot implementation faces several challenges that become increasingly problematic as systems scale
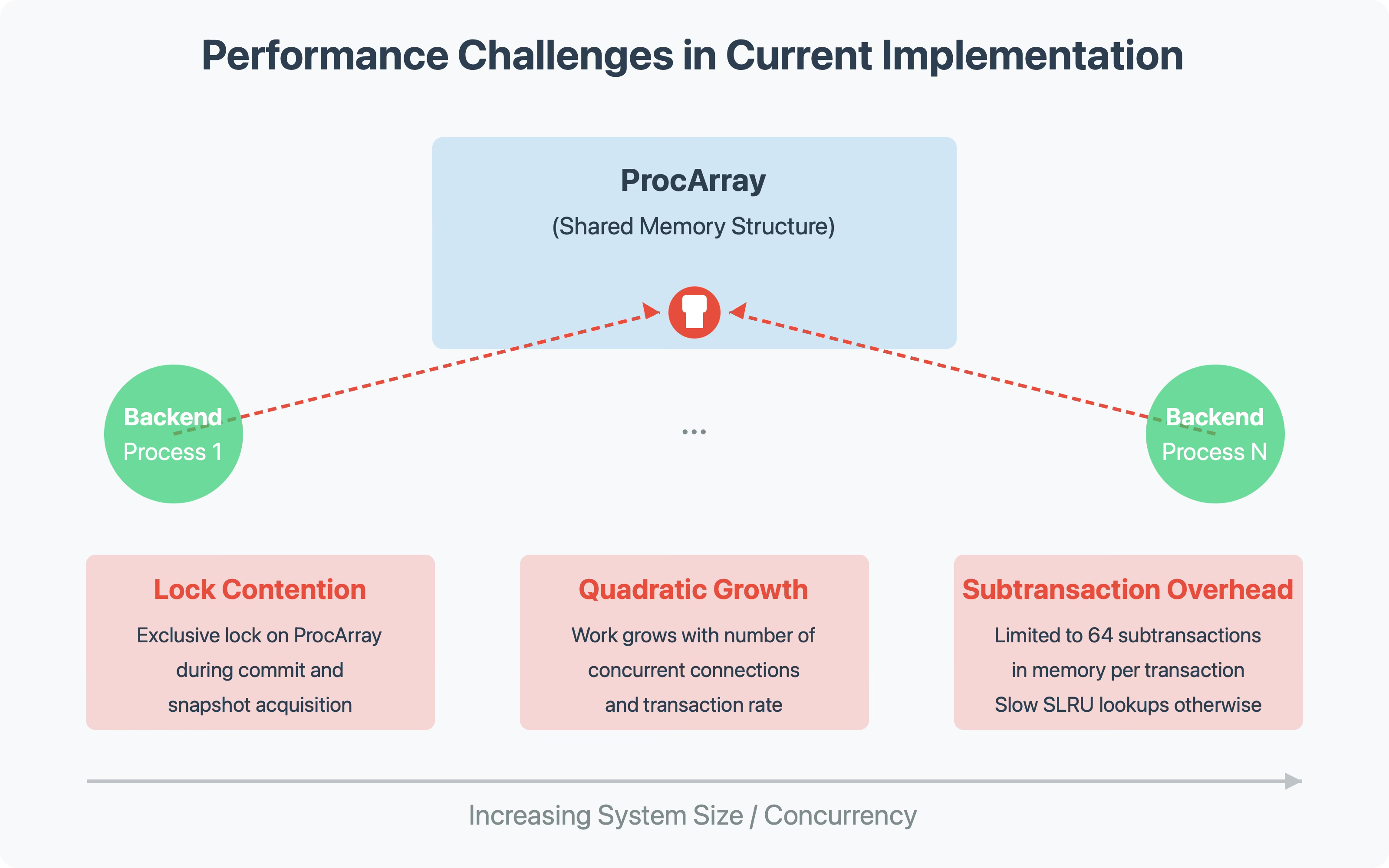
Scalability Limitations
The current implementation requires exclusive locks on the ProcArray during crucial operations. As the number of CPUs, concurrent connections, and transaction rates increase, contention for this lock becomes a bottleneck.
Each new snapshot must build an increasingly larger picture of running transactions, and the work grows quadratically with system size. While current optimizations have mitigated these issues for most users, PostgreSQL is running out of tricks to make this approach scale further.
Subtransaction Overhead
PostgreSQL supports subtransactions (nested transactions using SAVEPOINT), which add complexity to the snapshot mechanism. The current implementation stores subtransaction IDs in shared memory, with a limit of 64 subtransactions per top-level transaction.
When this limit is exceeded, PostgreSQL must use a different mechanism that significantly impacts performance, especially on replicas. Each row visibility check might require looking up the top-level transaction ID from the subtransaction, adding overhead to every row access.
Inconsistent Commit Order Between Primary and Replica
A particularly thorny issue arises from the fact that commit order on primaries and replicas can differ. On the primary, transactions become visible in the order they acquire the ProcArray lock during commit. On replicas, they become visible in the order they arrive via the transaction log.
This discrepancy is especially pronounced when mixing transactions with different synchronous_commit settings:
# On primary:
SET synchronous_commit = off; # Becomes visible immediately after WAL record is generated
SET synchronous_commit = on; # Waits for WAL to be flushed and possibly replicated
With synchronous_commit=off, transactions become visible earlier on the primary than on replicas. With synchronous_commit=on, the timing is more closely matched. This means the same application might see a different state of the database depending on whether it's connected to the primary or a replica.
Phantom Transactions During Synchronous Replication
Another critical issue occurs during synchronous replication when a client disconnects during commit. Consider this scenario:
A client executes
COMMITwith synchronous replication enabledPostgreSQL writes the commit record to the WAL and waits for acknowledgment from the replica
The replica confirms receipt
Before PostgreSQL can notify the client of success, the client connection fails
The primary marks the transaction as completed
If a failover occurs at this point, the transaction might not be visible on the newly promoted replica
This can lead to subtle inconsistencies where an application sees a transaction as committed before a failover, but not afterward.
Distributed Systems Limitations
Perhaps most importantly, the current snapshot implementation doesn't work well for distributed systems. A distributed ProcArray would face insurmountable challenges with network latency, partial failures, and coordination overhead.
Enter CSN Snapshots: A Hybrid Approach
To address these challenges, there's a proposal to implement what's called "CSN snapshots" (Commit Sequence Number snapshots).
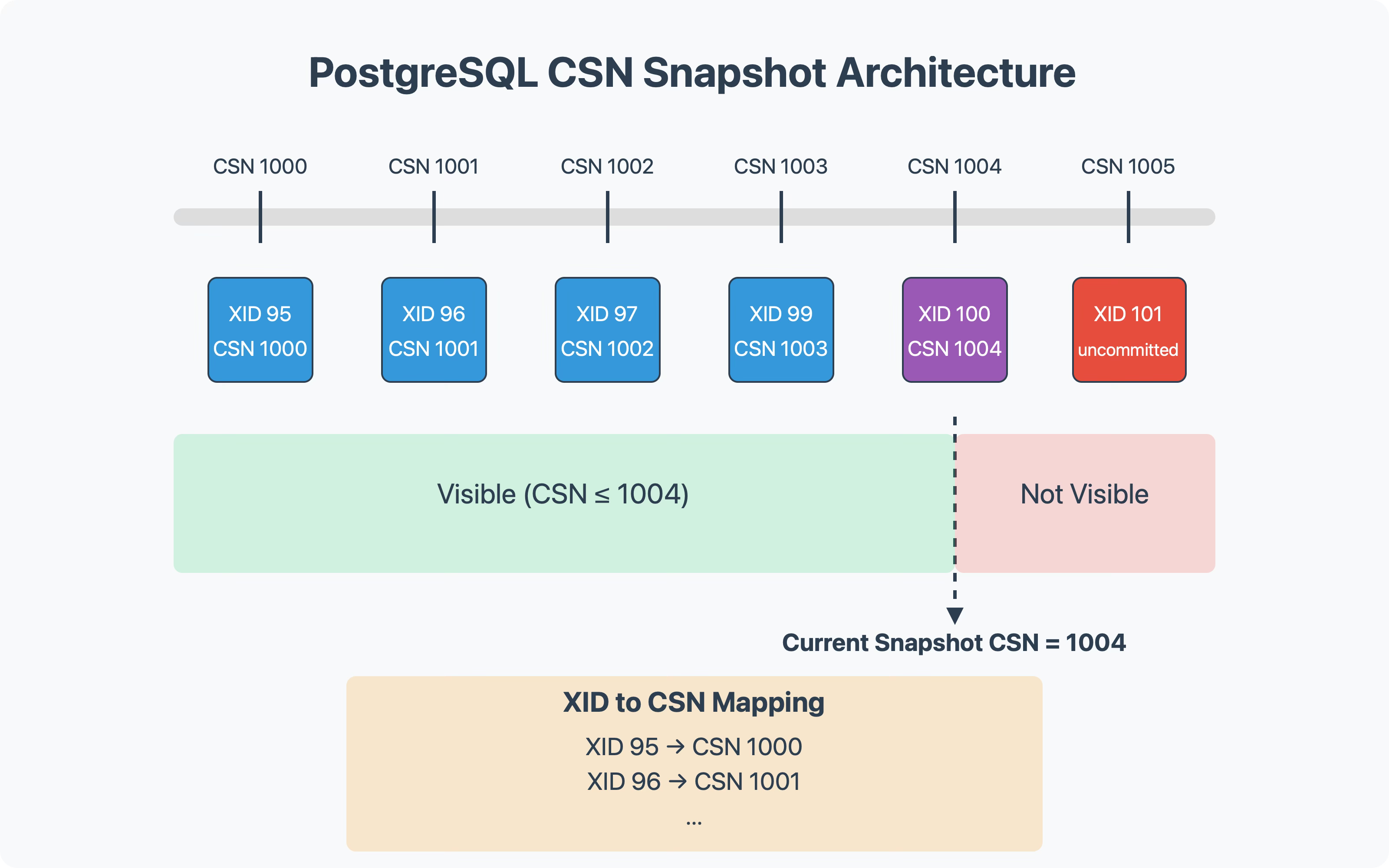
This approach has been successfully used in distributed databases like Google Spanner, YugabyteDB, and CockroachDB.
The Core Concept
Instead of tracking individual running transactions, CSN snapshots work by assigning a monotonically increasing number to each transaction when it commits. A snapshot is then simply a CSN value—it can see all transactions with CSN values less than or equal to its own.
For this approach to work, two main conditions must be satisfied:
CSN values must always increase (never go backward)
There must be a way to map from a transaction ID stored on a row to its corresponding CSN
Options for CSN Values
Several options exist for what value to use as the CSN:
Simple Counter: A straightforward incrementing value, simple to manage in a single system
WAL Position (LSN): Using the Write-Ahead Log position of the commit record, which is naturally communicated to standby servers
Wall Clock Time: Using timestamps with additional mechanisms to ensure monotonicity
Each option has trade-offs. A simple counter is easy to implement but requires coordination in distributed settings. WAL positions tie visibility to log order, which may not always be desirable. Wall clock time provides nice properties for distributed systems but requires careful handling to ensure monotonicity.
Mapping XIDs to CSNs
To implement CSN snapshots, PostgreSQL would need a way to map from the XID stored on a row to its corresponding CSN. A straightforward approach would be to store this mapping in a shared memory structure, similar to how subtransaction information is currently tracked.
Interestingly, the CSN value could replace the current pg_xact entry, which simply indicates whether a transaction committed or aborted:
No CSN value = not committed
Has CSN value = committed and became visible at that CSN
After sufficient time has passed, the CSN mapping could be compressed into the binary committed/aborted information, saving space.
Simplified Visibility Checks
With CSN snapshots, visibility checks become straightforward:
Look up the CSN for the row's XID
If the CSN is less than or equal to the snapshot's CSN, the row is visible (assuming it's not deleted by a transaction visible to the snapshot)
If greater, the row is not visible
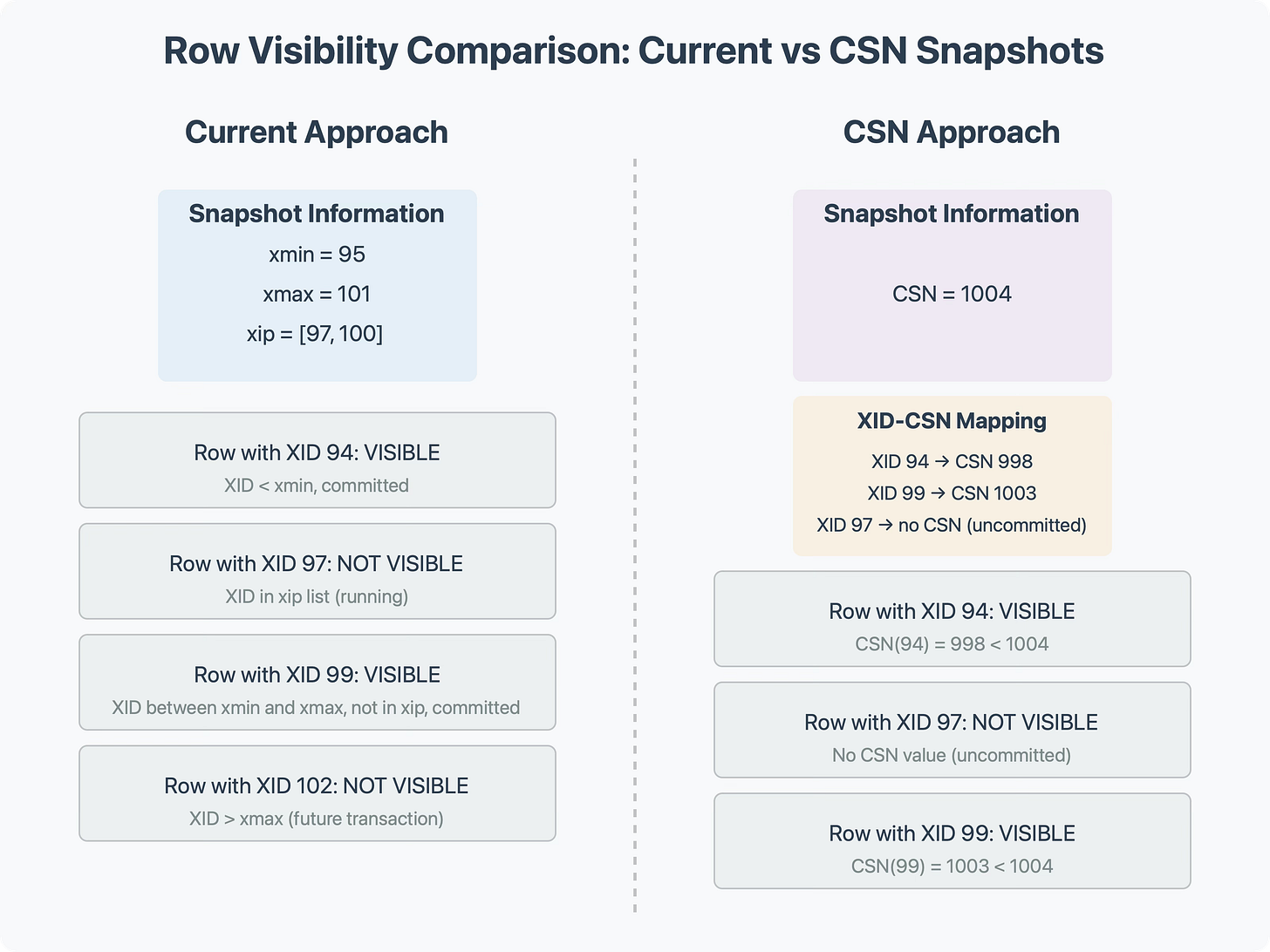
Row Visibility Comparision
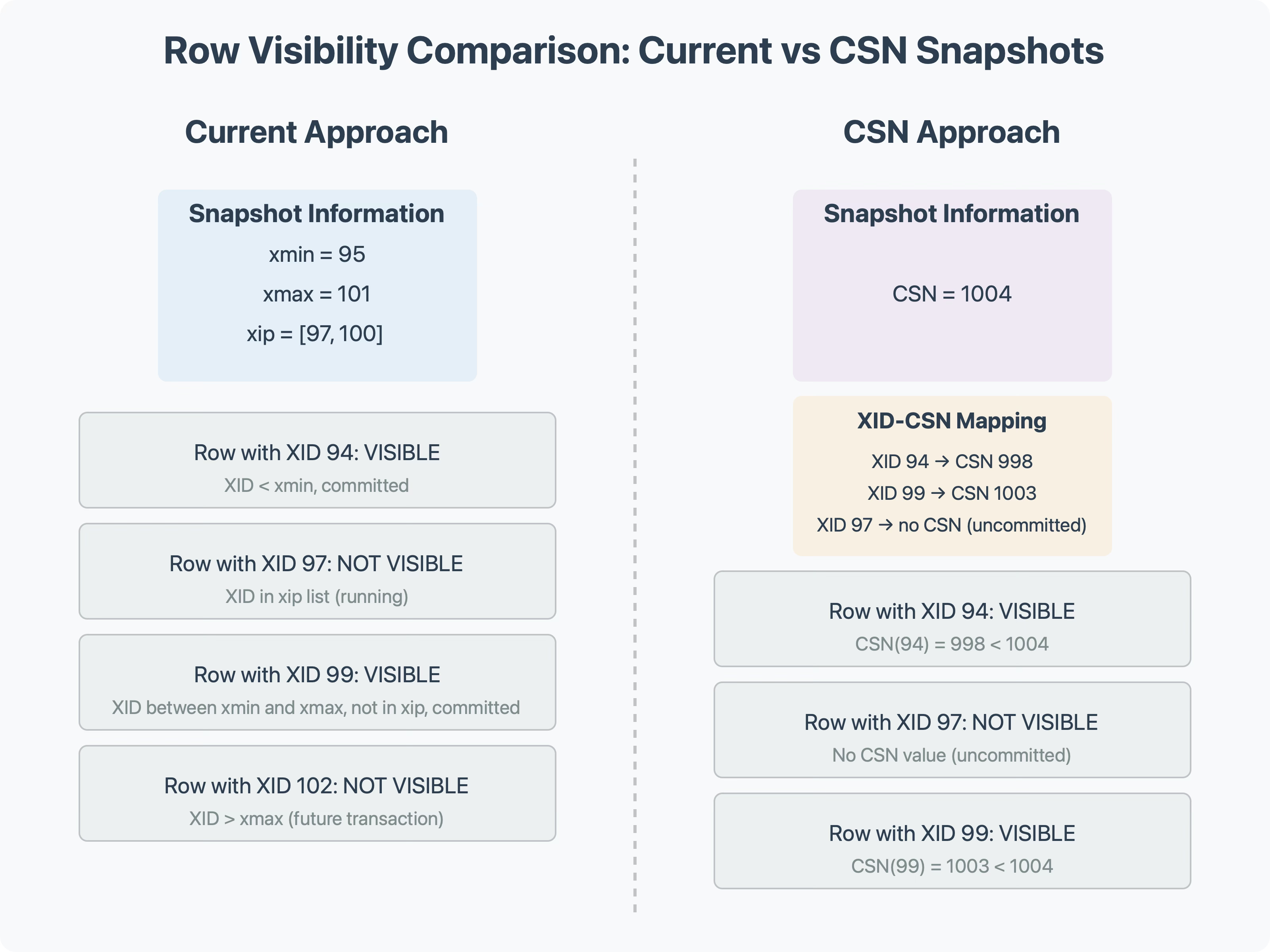
The XID-to-CSN lookup could potentially become a performance bottleneck, but there are ways to optimize this, which we'll discuss later.
Addressing Current Challenges with CSN Snapshots
Let's see how the CSN approach addresses each of the challenges identified earlier.
Scalability Improvement
By eliminating the need to track all running transactions in every snapshot, CSN snapshots dramatically reduce the amount of work needed to create a snapshot. Instead of building an increasingly large list of running transactions, a snapshot is simply a single number.
The process of making transactions visible can also be more efficient. Instead of acquiring an exclusive lock on the ProcArray, transactions would update a single atomic counter or timestamp.
Subtransaction Handling
For subtransactions, the CSN approach offers two options:
Update every subtransaction XID with the top-level transaction's CSN on commit
Use special CSN values to indicate that an XID is a subtransaction, encoding the parent XID within the CSN
The latter approach allows avoiding subtransaction SLRUs (Simplified Least Recently Used caches) entirely, addressing a significant performance pain point.
Synchronous Commit and Visibility Order
While CSN snapshots don't eliminate the fundamental trade-off between consistency and performance, they provide clearer options for managing it:
Default behavior: Wait until all transactions with lower CSNs have completed
Fire-and-forget commits: Skip waiting for visibility, with the understanding that the transaction won't be immediately visible
This creates a cleaner separation between commit durability (writing to disk) and commit visibility (becoming visible to other transactions).
For applications that need to read their own writes immediately but don't want to wait for durability, PostgreSQL could provide options to read uncommitted data that is likely to commit successfully.
Distributed Systems Support
For distributed systems, CSN snapshots provide a foundation for consistent snapshots across shards.
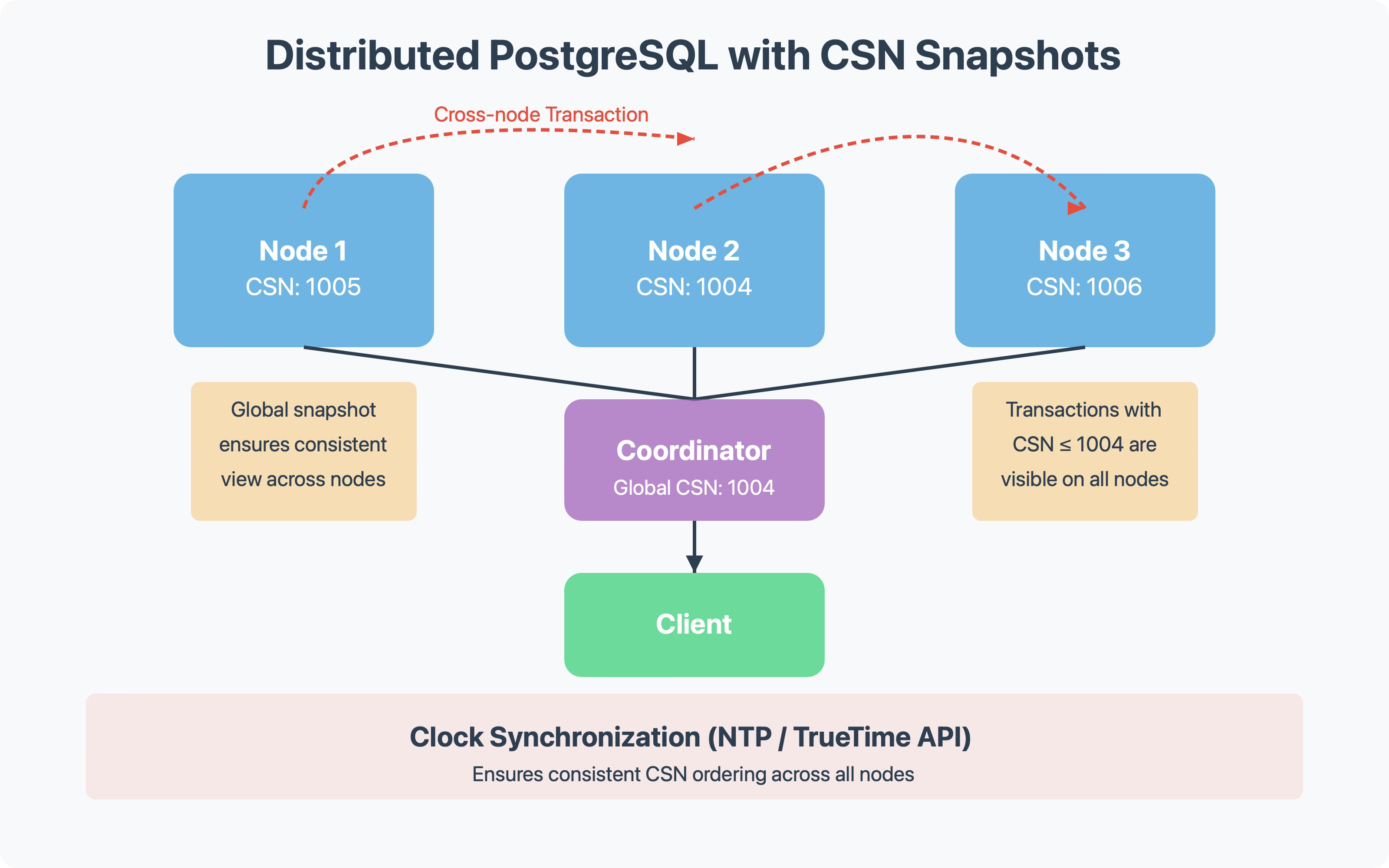
Two main approaches exist:
Google Spanner's TrueTime API: Use time with error bounds, waiting out the uncertainty to ensure correct ordering
YugabyteDB's Hybrid Time: Use NTP-synchronized clocks with monotonicity guarantees and eager communication of timestamps
Both approaches enable consistent snapshots across distributed nodes without requiring synchronous coordination for every transaction.
Optimizing CSN Lookups
As mentioned earlier, looking up CSN values for XIDs could become a performance bottleneck. Here's a sophisticated approach to addressing this:
Ring Buffer: Store recent CSN values in a ring buffer in shared memory, allowing direct lookups without SLRUs
XIP Array: Convert older XIDs to a traditional snapshot format (XIP array) for long-running transactions
Batch Operations: Process CSN values in batches (e.g., converting to
pg_xactentries) for efficiency
This hybrid approach would give the benefits of CSN snapshots while minimizing the overhead of XID-to-CSN lookups.
Implementation Status
While the CSN snapshot approach is promising, it's still in development. Work is underway on:
A patch implementing global snapshots, assigning CSN during proc array exit and writing it to the WAL
Work on making CSN snapshots available on standby servers
The goal is to have this functionality available in PostgreSQL 18.
Practical Implications for PostgreSQL Users
If implemented, CSN snapshots would provide several practical benefits:
More Predictable Performance Under Load
The removal of the ProcArray bottleneck would allow more linear scaling with increased concurrency, benefiting applications with many short transactions.
Improved Subtransaction Performance
Applications using nested transactions or savepoints would see better performance, especially with many subtransactions.
More Consistent Behavior Between Primary and Replicas
The consistent order of transaction visibility would make behavior more predictable when switching between primary and replica connections.
Foundation for Distributed PostgreSQL
Most excitingly, CSN snapshots would provide a foundation for true distributed PostgreSQL deployments, enabling consistent snapshots across shards.
Exercises and Challenges
To better understand these concepts in practice, consider trying these exercises:
Analyze current snapshot behavior: Use
pg_stat_activityandtxid_current()to observe transaction IDs in a running system:
SELECT pid, txid_current(), query
FROM pg_stat_activity
WHERE state = 'active';
Observe commit order inconsistencies: Set up synchronous replication with a mix of
synchronous_commitsettings and observe the order of visibility on primary vs. replica.Benchmark subtransaction overhead: Create a test case with varying numbers of savepoints to observe the performance cliff when exceeding the in-memory subtransaction limit.
Test snapshot isolation anomalies: Create test cases demonstrating classic anomalies like non-repeatable reads or phantom reads, and observe how different isolation levels affect them.
Key Takeaways
PostgreSQL's current snapshot implementation has served well for 26 years but faces fundamental scalability challenges.
The most significant issues include
ProcArraylock contention, subtransaction overhead, inconsistent commit order between primary and replicas, and limited distributed systems support.CSN snapshots offer a promising alternative, assigning a commit sequence number to transactions when they commit and using this for visibility checks.
This approach has been proven in distributed databases and provides a cleaner model for handling commit visibility.
Optimizations like ring buffers and incremental snapshot building can mitigate potential performance impacts of CSN lookups.
Most importantly, CSN snapshots would provide a foundation for true distributed PostgreSQL deployments, enabling consistent snapshots across shards.
The evolution of PostgreSQL's snapshot implementation represents a fascinating case study in database design—balancing theoretical consistency guarantees with practical performance considerations. As workloads continue to grow in both size and complexity, these foundational mechanisms become increasingly important for PostgreSQL's continued success in demanding environments.
References
PostgreSQL Documentation: Transaction Isolation
PostgreSQL Wiki: MVCC
Google Spanner: TrueTime and External Consistency
YugabyteDB: Hybrid Logical Clocks and Ordering Events in Distributed Systems
What tool is used to draw these beautiful illustrations?