
Linux Process and Thread Creation: System Call Architecture
Understanding the Unified Task Model in Modern Linux Kernels

Linux handles process and thread creation through a unified approach that might surprise developers coming from other operating systems. In fact, for the Linux kernel itself there's absolutely no difference between what userspace sees as processes (the result of fork) and as threads (the result of pthread_create). Both are represented by the same data structures and scheduled similarly.
The kernel treats everything as tasks, represented by the task_struct data structure. In Linux, threads are just tasks that share some resources, most notably their memory space; processes, on the other hand, are tasks that don't share resources.
The Clone System Call: Foundation of Process and Thread Creation
At the heart of Linux's process and thread creation lies the clone() system call. Both fork and clone map to the same underlying kernel mechanism, and both of these are in turn implemented using the clone system call.
System Call Hierarchy
The system call hierarchy represents the layered architecture of Linux process and thread creation mechanisms. At the userspace level, applications invoke familiar functions like fork(), pthread_create(), and vfork(), but these are merely high-level interfaces that eventually converge on a single kernel mechanism.
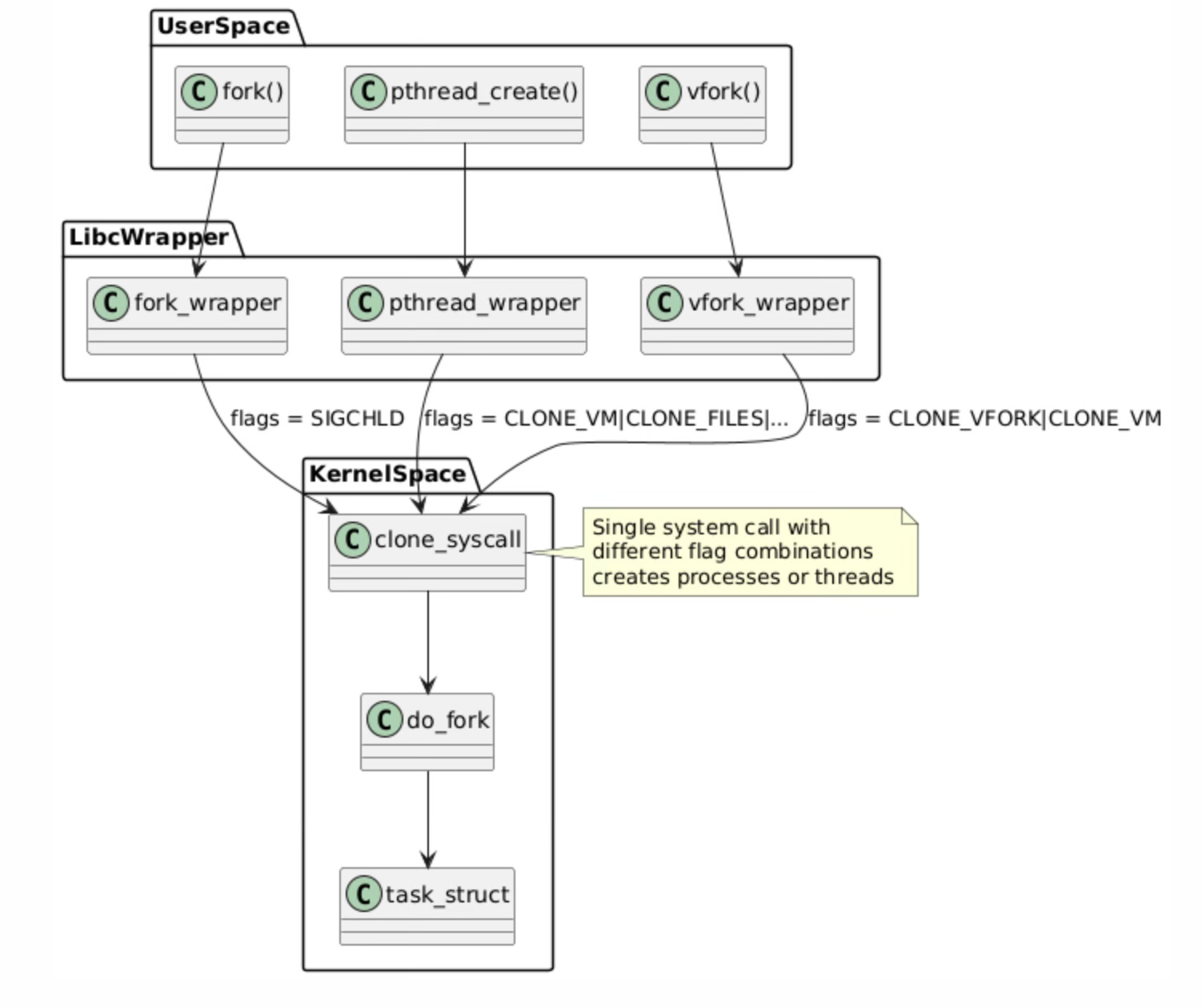
The libc wrapper layer serves as an abstraction that translates these different API calls into appropriate clone() system call invocations with specific flag combinations.
This unified approach demonstrates the elegance of the Linux kernel design. Rather than implementing separate kernel pathways for process and thread creation, the kernel provides a single, flexible clone() system call that can create tasks with varying degrees of resource sharing.
The do_fork() kernel function handles the actual task creation logic, allocating and initializing the fundamental task_struct data structure that represents every schedulable entity in the system. This design reduces code duplication in the kernel while providing maximum flexibility for different use cases.
Clone Flags and Their Effects
The clone() system call accepts various flags that determine what resources the parent and child will share. Here are the key flags:
CLONE_VM: When set, the child shares the parent's virtual memory space. This flag is fundamental to thread creation because it enables multiple execution contexts to operate within the same address space. Without CLONE_VM, each task receives its own copy of the parent's memory mappings through the copy-on-write mechanism.
The virtual memory descriptor (struct mm_struct) is shared between parent and child when this flag is present, meaning modifications to memory mappings, heap allocations, and stack operations are immediately visible to both tasks.
The implementation of CLONE_VM involves incrementing the reference count on the parent's memory management structure rather than duplicating it. This sharing extends beyond just the data pages to include the entire virtual memory layout, including code segments, data segments, heap, and memory-mapped files.
However, each task still maintains its own stack space and register context, allowing for independent execution paths while sharing the same memory environment.
CLONE_FILES: If CLONE_FILES is set, the calling process and the child processes share the same file descriptor table. File descriptors always refer to the same files in the calling process and in the child process.
This means that when one task opens, closes, or modifies a file descriptor, the change is immediately visible to all other tasks sharing the same file table. The kernel accomplishes this by sharing the files_struct structure, which contains the file descriptor array and associated metadata.
This sharing mechanism has important implications for file operations. When multiple threads share file descriptors, they share not only the file handles but also the file position pointers. This means that if one thread reads from a file descriptor, it advances the file position for all other threads sharing that descriptor. Applications must coordinate access to shared file descriptors through synchronization mechanisms to prevent race conditions and ensure predictable behavior.
CLONE_SIGHAND: If CLONE_SIGHAND is not set, the child process inherits a copy of the signal handlers of the calling process at the time clone() is called. Calls to sigaction(2) performed later by one of the processes have no effect on the other process. Since Linux 2.6.0-test6, flags must also include CLONE_VM.
This flag enables sharing of signal disposition tables between tasks, which is essential for proper thread behavior where signal handlers should be process-wide rather than per-thread.
The signal handling architecture in Linux becomes complex when CLONE_SIGHAND is combined with other flags. While signal handlers are shared, each task maintains its own signal mask and pending signal set. This design allows for per-thread signal masking while maintaining consistent signal handler behavior across all threads in a process.
The kernel enforces the requirement that CLONE_SIGHAND must be accompanied by CLONE_VM because signal handlers often access shared memory, and having different memory spaces would create undefined behavior.
CLONE_THREAD: Creates a thread in the same thread group as the parent. This flag is crucial for implementing POSIX threads semantics, where multiple threads belong to the same process and share a process ID from the perspective of external observers. When CLONE_THREAD is set, the new task joins the thread group of the parent, sharing the same thread group ID (TGID) and appearing as a single process to userspace tools.
The thread group mechanism affects various aspects of process management, including signal delivery, process accounting, and resource limits. Signals sent to the process ID are delivered to the entire thread group, and resource limits are applied at the thread group level rather than per-thread.
This creates the illusion of a single process with multiple execution contexts, which aligns with the POSIX threading model expected by most applications.
Process Creation with Fork
The fork() system call creates a new process by duplicating the calling process, implementing the classic Unix process creation model. When fork() is invoked, it internally calls clone() with the SIGCHLD flag, which specifies that the parent should receive a SIGCHLD signal when the child terminates.
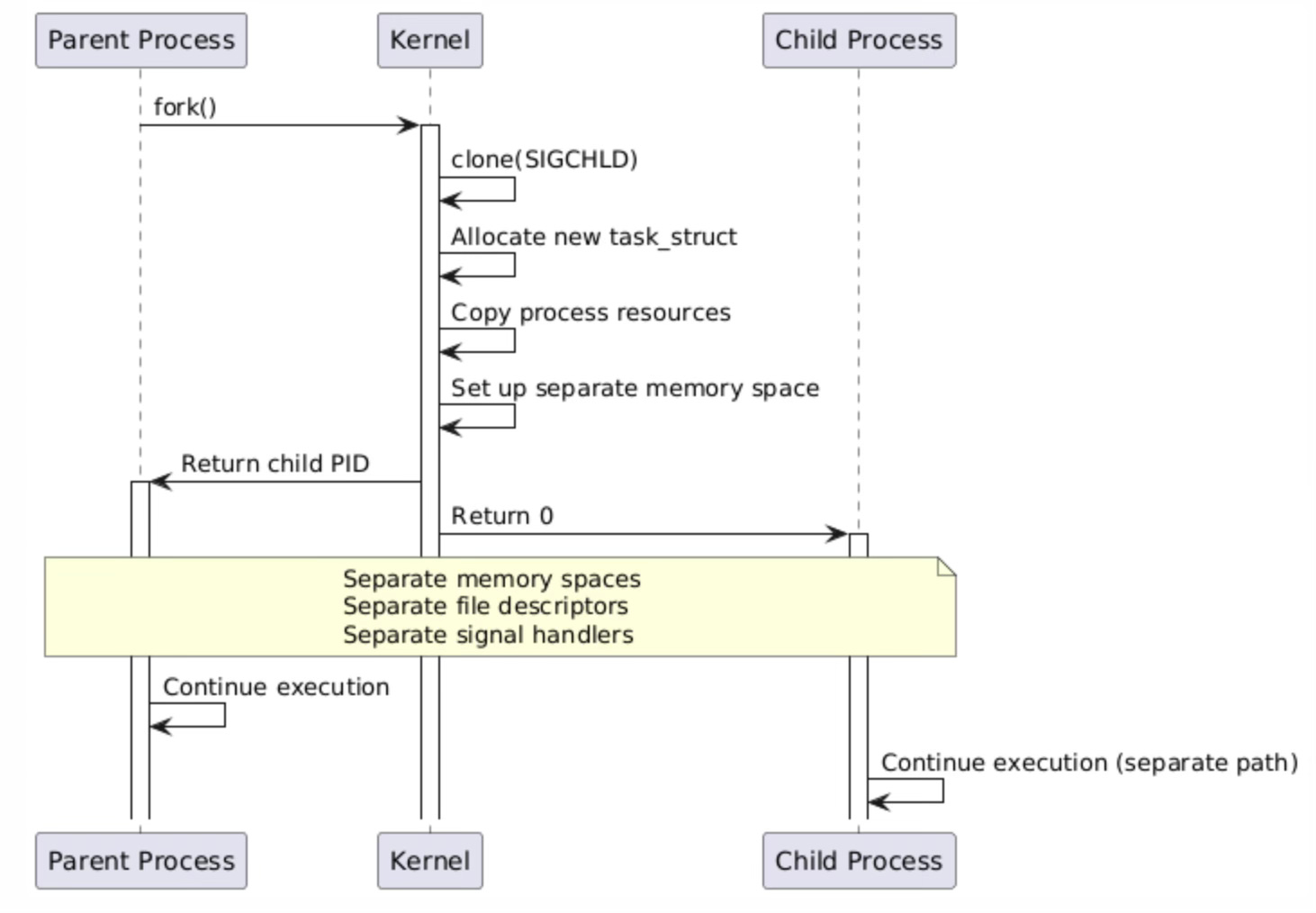
This mechanism provides the foundation for process hierarchies and enables parent processes to monitor and manage their children through wait() family system calls.
The kernel's implementation of fork() involves several critical steps that ensure proper process isolation. First, a new task_struct is allocated and initialized with a copy of the parent's process information. The kernel then duplicates the parent's virtual memory space using copy-on-write semantics, meaning that initially both processes share the same physical memory pages marked as read-only. When either process attempts to write to a shared page, the kernel generates a page fault, creates a private copy of the page, and allows the write to proceed. This lazy copying approach optimizes memory usage and reduces the overhead of process creation.
The separation of resources in fork() extends beyond memory to include file descriptors, signal handlers, and process credentials. Each forked process receives its own copy of the parent's file descriptor table, allowing independent file operations without affecting the parent. Signal handlers are also duplicated, enabling each process to customize its signal handling behavior independently. This complete resource isolation ensures that processes cannot accidentally interfere with each other's operation, providing the security and stability guarantees expected from the Unix process model.
Thread Creation with pthread_create
The pthread_create() function represents the POSIX threads implementation for creating new threads within a process. Unlike fork(), pthread_create() operates through the pthread library, which serves as a userspace wrapper around the kernel's clone() system call.
The pthread library carefully orchestrates the thread creation process, managing thread-specific resources like stack allocation, thread-local storage setup, and cleanup handler registration before invoking the kernel to create the actual task.
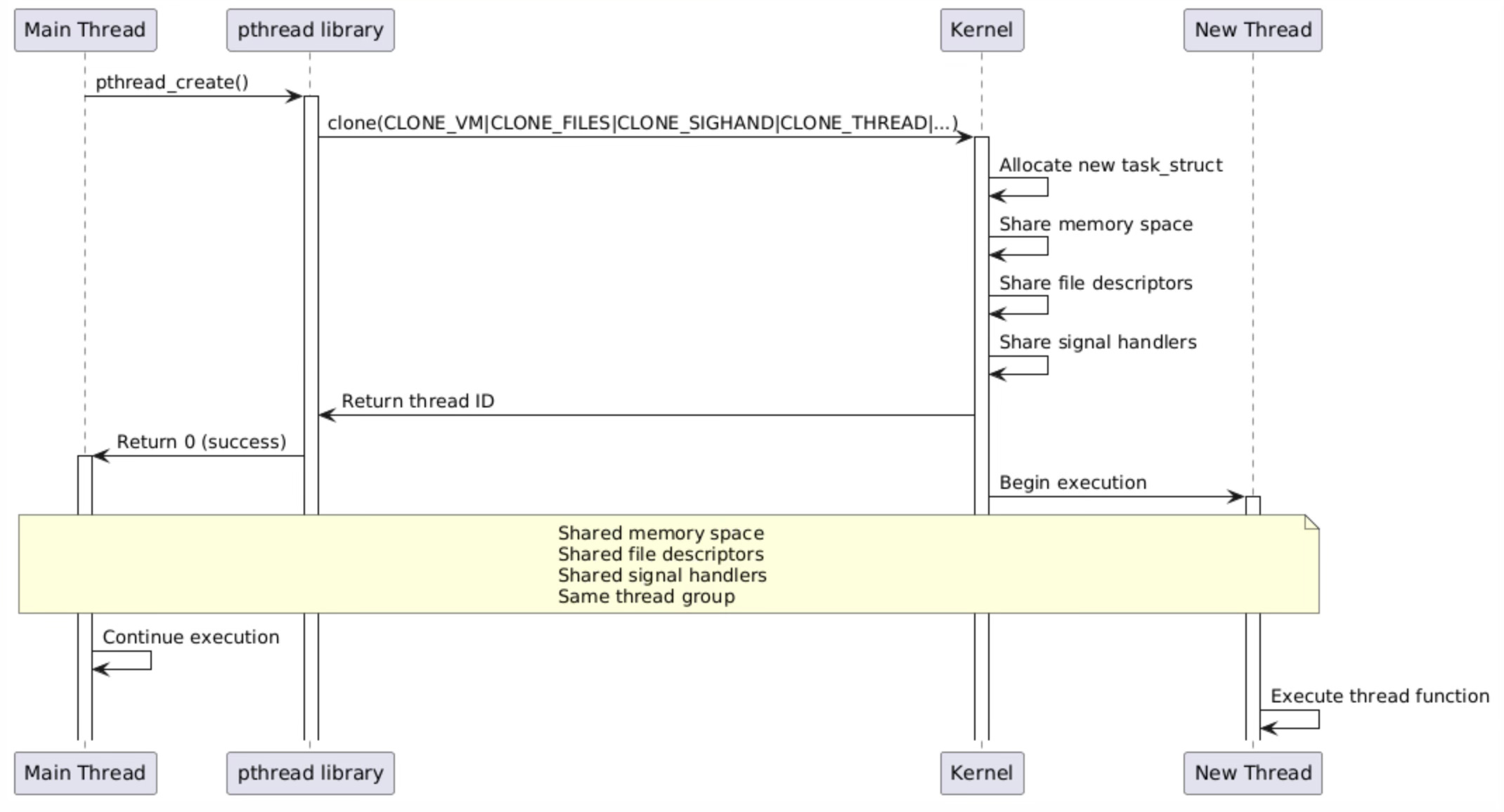
When pthread_create() calls clone(), it passes a specific combination of flags that enable comprehensive resource sharing between the parent and child threads. The CLONE_VM flag ensures that both threads operate within the same virtual address space, allowing them to share global variables, heap allocations, and memory-mapped files.
CLONE_FILES enables sharing of file descriptors, so file operations performed by one thread are immediately visible to all other threads in the process. CLONE_SIGHAND ensures that signal handlers are shared, maintaining consistent signal behavior across the entire thread group.
The pthread library handles several critical aspects of thread management that the kernel clone() system call does not directly address. This includes allocating and managing thread stacks, typically using mmap() to create stack segments with guard pages to detect stack overflow conditions.
The library also manages thread-local storage (TLS) blocks, which provide per-thread storage for variables marked with __thread specifiers. Additionally, pthread_create() sets up the thread's cleanup handler chain and synchronization primitives, ensuring that resources can be properly released when the thread terminates either normally or through cancellation.
Resource Sharing Matrix
The following table shows what resources are shared between different creation methods:
Low-Level Implementation Details
Task Structure Creation
The clone() system call implementation in the Linux kernel follows a carefully orchestrated sequence of operations that transforms a single execution context into two independent but potentially resource-sharing tasks. The process begins with rigorous flag validation, where the kernel verifies that the requested flag combinations are logically consistent and supported.
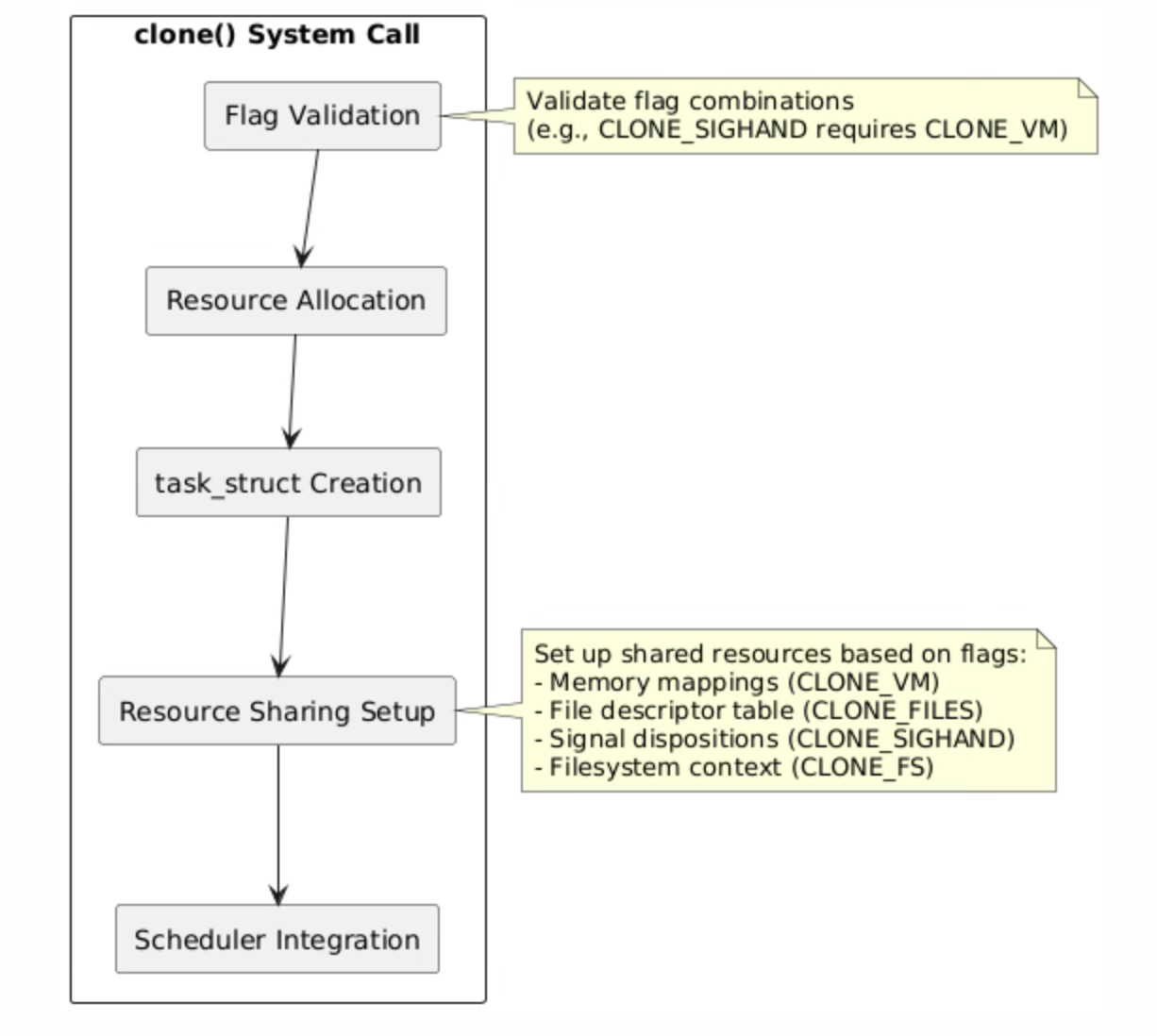
For instance, certain flags like CLONE_SIGHAND require CLONE_VM because signal handlers often access shared memory regions, and having different memory spaces would create undefined behavior when signal handlers execute.
Resource allocation represents the most complex phase of task creation, involving the allocation and initialization of the new task_struct, which serves as the kernel's representation of every schedulable entity. The task_struct contains hundreds of fields representing everything from process credentials and memory management information to scheduling parameters and signal handling state.
The kernel must carefully initialize these fields based on the requested sharing semantics, either copying values from the parent or establishing shared references to parent resources.
The resource sharing setup phase configures the specific sharing relationships requested through the clone flags. When CLONE_VM is specified, the kernel increments the reference count on the parent's memory management structure (mm_struct) rather than creating a copy, establishing shared virtual memory semantics.
Similarly, CLONE_FILES causes the new task to share the parent's file descriptor table by incrementing the reference count on the files_struct. This reference counting mechanism ensures that shared resources remain valid as long as any task references them, and are automatically freed when the last reference is released.
Integration with the scheduler represents the final phase where the new task becomes eligible for execution. The kernel adds the task to the appropriate runqueue based on its scheduling policy and priority, initializes its scheduling statistics, and sets up any necessary load balancing data structures.
The scheduler integration must account for the task's resource sharing relationships, as tasks sharing memory or other resources may benefit from being scheduled on the same CPU or CPU complex to improve cache locality and reduce synchronization overhead.
Memory Management Differences
The memory management models for processes and threads represent fundamentally different approaches to resource isolation and sharing. In the process creation model, each new process receives its own complete virtual address space, initially populated through copy-on-write semantics that defer actual memory copying until write operations occur.

This approach provides strong isolation guarantees, ensuring that processes cannot accidentally corrupt each other's memory, but requires significant memory management overhead for large processes with extensive memory mappings.
The copy-on-write mechanism operates at the page level, where initially both parent and child processes share the same physical memory pages marked as read-only in their respective page tables. When either process attempts to write to a shared page, the hardware generates a page fault that the kernel handles by allocating a new physical page, copying the original page's contents, and updating the page table entry to point to the new private copy.
This lazy copying approach optimizes memory usage by avoiding unnecessary copying of pages that are never modified, but introduces latency spikes when copy-on-write faults occur during execution.
In contrast, the thread creation model establishes a single shared virtual address space accessible to all threads within the process. This sharing extends to all memory regions including the heap, global variables, and memory-mapped files, but each thread maintains its own private stack space to enable independent function call chains and local variable storage.
The kernel allocates stack space for each thread using mmap() system calls, typically creating stack segments with guard pages at the boundaries to detect stack overflow conditions. Thread stacks are usually allocated from the process's virtual address space in a downward-growing pattern, with each stack separated by unmapped guard regions that trigger segmentation faults if accessed.
Performance Characteristics
Creation Time Comparison
Thread creation is significantly faster than process creation because:
No memory space duplication: Threads share the same virtual address space
No file descriptor table copying: Threads share the same file descriptor table
Minimal resource allocation: Only stack space and thread-specific data need allocation
The performance differential between thread and process creation stems from the fundamental differences in resource management overhead. Process creation through fork() requires the kernel to duplicate numerous data structures including the virtual memory area (VMA) structures that describe all memory mappings, the file descriptor table containing references to all open files, and various process-specific metadata. Even with copy-on-write optimizations, the kernel must still traverse and duplicate complex data structures, create new page table entries, and establish separate resource accounting structures.
Thread creation optimization focuses on minimizing the overhead of creating new execution contexts within existing resource frameworks. The pthread library pre-allocates thread stacks using efficient memory mapping techniques, often maintaining pools of available stacks to avoid repeated system calls. The kernel's clone() implementation for threads primarily involves allocating and initializing a new task_struct while establishing shared references to existing resource structures, resulting in significantly reduced computational overhead compared to full process duplication.
Context Switching Performance
Context switching performance represents one of the most significant advantages of thread-based architectures over process-based designs. When the scheduler switches between processes, it must perform a complete memory management context switch, including loading new page table roots, flushing translation lookaside buffers (TLBs), and potentially invalidating various CPU cache levels. This memory management overhead can consume hundreds of CPU cycles and create substantial latency spikes, particularly on systems with large working sets that stress the TLB and cache hierarchies.
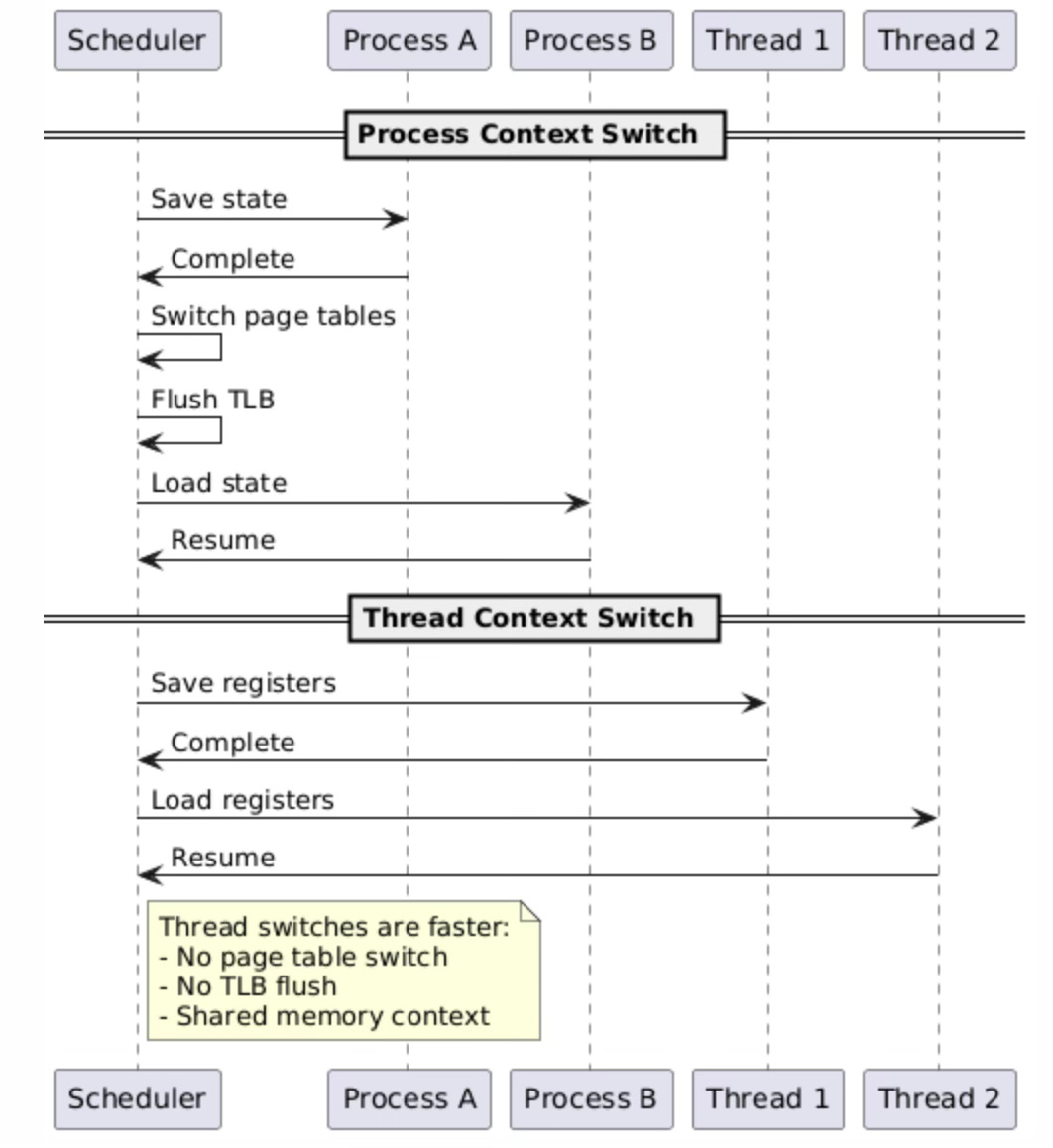
Thread context switches within the same process avoid most memory management overhead because threads share the same virtual address space and therefore the same page table structures. The scheduler only needs to save and restore CPU registers, stack pointers, and thread-specific state, while leaving the memory management unit configuration unchanged.
This streamlined switching process reduces context switch latency by an order of magnitude compared to process switches, enabling higher thread switching frequencies and more responsive multithreaded applications. The shared memory context also improves cache locality, as threads accessing the same data structures benefit from cache lines already loaded by other threads in the same process.
Advanced Clone Flags and Use Cases
Creating Lightweight Processes
One flag in particular stands out which is CLONE_THREAD. Different flag combinations enable various lightweight process models:
Container-like isolation:
clone(child_func, stack_ptr,
CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWNET,
NULL);Shared memory processes:
clone(child_func, stack_ptr,
CLONE_VM | CLONE_FILES,
NULL);Full thread creation:
clone(child_func, stack_ptr,
CLONE_VM | CLONE_FILES | CLONE_SIGHAND |
CLONE_THREAD | CLONE_SYSVSEM,
NULL);The flexibility of the clone() system call enables the creation of lightweight processes that fall between traditional processes and threads in terms of resource sharing and isolation. These hybrid execution models prove particularly valuable for specialized applications such as container runtimes, user-space network stacks, and high-performance computing frameworks that require fine-grained control over resource sharing policies. The namespace-related flags (CLONE_NEWPID, CLONE_NEWNS, CLONE_NEWNET) enable the creation of isolated execution environments that form the foundation of modern containerization technologies.
Container-like isolation demonstrates how clone() flags can create processes that appear completely isolated from the host system perspective while still sharing certain resources for efficiency. The CLONE_NEWPID flag creates a new process ID namespace where the child process becomes PID 1 within its own namespace, enabling process tree isolation without requiring full virtualization. CLONE_NEWNS creates a separate mount namespace, allowing the child to have its own filesystem view, while CLONE_NEWNET provides network namespace isolation with separate network interfaces and routing tables.
Shared memory processes represent an intermediate model where processes share memory space but maintain separate file descriptor tables and signal handlers. This configuration proves useful for applications that need shared memory performance but require isolation for file operations or signal handling. The selective sharing enables custom process architectures where different aspects of process state can be shared or isolated based on application requirements, providing more flexibility than the binary choice between full process isolation and complete thread sharing.
Security and Isolation Considerations
Namespace Isolation
Linux namespaces provide a powerful mechanism for creating isolated execution environments without the overhead of full virtualization. When clone() is invoked with namespace creation flags, the kernel establishes separate instances of global system resources, creating the illusion of independent system environments while sharing the underlying kernel infrastructure. This approach enables container technologies to provide strong isolation guarantees while maintaining near-native performance characteristics.
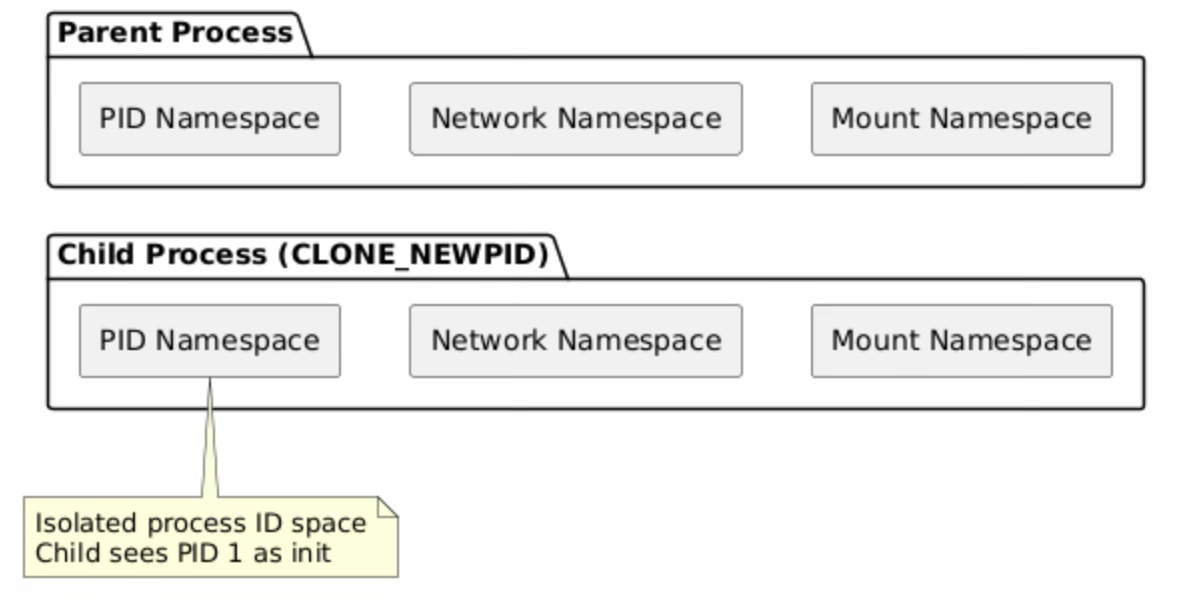
The PID namespace isolation creates separate process ID spaces where each namespace maintains its own PID allocation and process hierarchy. Within a new PID namespace, the first process becomes PID 1 and assumes the role of init, responsible for reaping orphaned processes and handling system-level process management tasks. This isolation prevents processes in different namespaces from directly signaling or examining each other, providing security boundaries that contain potential attacks or resource exhaustion scenarios.
Network namespace isolation extends this model to network resources, providing each namespace with its own network interfaces, routing tables, firewall rules, and socket port spaces. This enables multiple processes to bind to the same port numbers without conflicts, and allows for complex network configurations where different namespaces can have completely different network topologies.
The combination of multiple namespace types enables sophisticated isolation scenarios where containers can have their own filesystem view, network configuration, and process space while still sharing the host kernel efficiently.
Signal Handling in Threads vs Processes
However, the calling process and child processes still have distinct signal masks and sets of pending signals. This creates important differences in signal handling:
Process model: Each process has independent signal handling Thread model: Signal handlers are shared, but signal masks are per-thread
The signal handling architecture in Linux becomes particularly complex when dealing with threads due to the hybrid nature of signal delivery and handling. While threads within a process share signal handlers through the CLONE_SIGHAND flag, each thread maintains its own signal mask, allowing for selective signal blocking on a per-thread basis. This design enables sophisticated signal handling strategies where certain threads can be designated as signal handlers while others block signals to avoid interruption during critical sections.
Signal delivery to multithreaded processes follows specific rules defined by the POSIX standard, where signals directed to the process are delivered to any thread that has not blocked the signal. This non-deterministic delivery model requires careful coordination between threads to ensure proper signal handling.
The kernel's signal delivery mechanism searches the thread group for eligible targets, potentially waking sleeping threads if necessary to deliver urgent signals. This complexity necessitates careful signal mask management and often leads to designs where a single thread handles all signals while others block them entirely.
Debugging and Observability
Identifying Task Relationships
Tools like ps, top, and /proc filesystem show the relationship between tasks:
# Show thread relationships
ps -eLf
# Show process tree
pstree -p
# Examine task details
cat /proc/PID/task/*/statCommon Pitfalls and Best Practices
Race Conditions in Shared Resources
When using clone() with shared resources, developers must handle synchronization:
// Proper synchronization for shared file descriptors
pthread_mutex_t fd_mutex = PTHREAD_MUTEX_INITIALIZER;
void safe_file_operation() {
pthread_mutex_lock(&fd_mutex);
// File operations here
pthread_mutex_unlock(&fd_mutex);
}Memory Leak Prevention
A new thread will be created and the syscall will return in each of the two threads at the same instruction, exactly like fork(). This similarity can lead to memory management issues if not handled carefully.
Conclusion
Linux's unified task model through the clone() system call provides a flexible foundation for both process and thread creation. Understanding the flag combinations and their effects on resource sharing is crucial for systems programming and performance optimization. The choice between processes and threads ultimately depends on the specific requirements for isolation, performance, and resource sharing in your application.
The kernel's approach of treating everything as tasks with varying degrees of resource sharing provides both simplicity in implementation and flexibility in use cases, from lightweight threads to fully isolated processes and everything in between.