
Process Scheduling Impacts on Lock Contention in Multi-Server Distributed Systems
How Operating System Preemption Creates Hidden Performance Bottlenecks in Concurrent Applications

Modern distributed applications face a subtle but critical performance challenge that stems from the intersection of operating system scheduling and concurrent programming. When processes across multiple servers compete for shared resources through locking mechanisms, the preemptive nature of modern operating systems can introduce significant delays that ripple throughout the entire system.
Consider a typical scenario: five servers running identical codebases, each spawning multiple processes that occasionally need exclusive access to shared resources. One process acquires a lock and begins its critical section work. Several other processes, both local and remote, queue up waiting for that lock to be released. Then the operating system scheduler decides it's time to give another process a turn, preempting the lock holder mid-execution.
What happens next illustrates a fundamental tension in modern computing. The waiting processes remain blocked, unable to proceed, while the lock holder sits dormant in the scheduler's queue. The lock that should have been held for microseconds might now be held for tens of milliseconds or longer, depending on system load and scheduling policies. This seemingly minor delay cascades through the distributed system, affecting throughput, latency, and resource utilization across all five servers.
Understanding Process Scheduling Fundamentals
Operating systems use preemptive multitasking to share CPU resources among competing processes. Linux, Windows, and other modern systems allocate time slices to running processes, typically ranging from 1 to 100 milliseconds depending on the scheduler implementation and system configuration. The Completely Fair Scheduler (CFS) in Linux, for example, aims to provide fair CPU time distribution but makes no guarantees about when a specific process will run next.
When a process exhausts its time quantum, the scheduler performs a context switch. The current process state gets saved, including CPU registers, memory mappings, and execution context. The scheduler then selects the next ready process based on its scheduling algorithm, considering factors like priority, niceness values, and fairness metrics.
This context switching overhead typically consumes several microseconds, but the real impact comes from the unpredictable delay before the preempted process runs again. Under light system load, a process might be rescheduled within a few milliseconds. Under heavy load, or with many competing processes, this delay can stretch to hundreds of milliseconds or even seconds.
The scheduler operates independently of application-level synchronization primitives. It doesn't know or care that a preempted process holds a critical lock that other processes need. From the scheduler's perspective, all processes are equal candidates for CPU time, regardless of their role in the application's locking hierarchy.
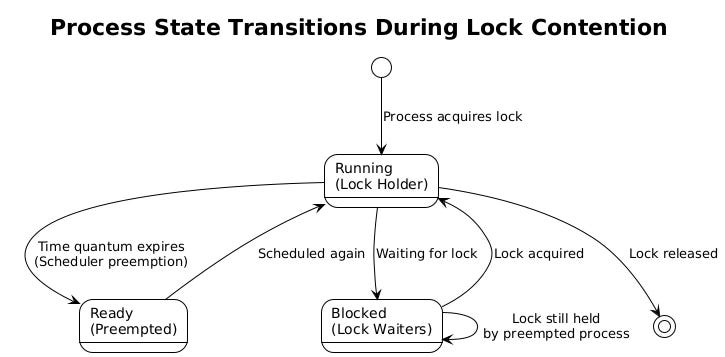
Lock Mechanisms and Their Vulnerabilities
Different locking mechanisms respond differently to scheduler preemption. Mutex locks typically use a combination of spinning and blocking. When a thread or process attempts to acquire a held mutex, it might spin briefly (busy-waiting) before transitioning to a blocked state where the scheduler can put it to sleep. This hybrid approach works well when locks are held for short periods, but becomes problematic when the holder gets preempted.
Spinlocks take a different approach, continuously polling the lock status in a tight loop. While this eliminates the overhead of blocking and waking up threads, it wastes CPU cycles when the lock holder is preempted. Multiple CPU cores might spin uselessly, consuming power and preventing other work from proceeding.
Semaphores and condition variables face similar challenges. When the process that should signal a condition variable or increment a semaphore gets preempted, waiting processes remain blocked indefinitely until the scheduler allows the signaling process to continue.
In distributed systems, these problems compound. A Redis-based distributed lock might use the SET command with expiration time to implement mutual exclusion across servers. If the lock-holding process gets preempted after acquiring the lock but before completing its work, processes on all five servers remain blocked. The lock might eventually expire, but this timeout mechanism is typically set to seconds or minutes to avoid premature release, meaning the delay still affects system performance.
ZooKeeper-based locks face similar issues. A process might successfully create an ephemeral sequential node to acquire a lock, then get preempted during the critical section. Other processes across the distributed system watch for changes to the lock node, but no changes occur until the holder is rescheduled and can delete its node.
Single Server Impact Analysis
On a single server, scheduler preemption affects both the lock holder and the waiting processes. When the holder gets preempted, waiting processes continue consuming resources in different ways depending on the lock implementation.
With blocking locks, waiting processes enter a sleep state, which seems efficient from a CPU perspective. However, these processes still consume memory and other system resources. More importantly, when the lock holder finally releases the lock, all waiting processes might wake up simultaneously, creating a thundering herd effect that can overwhelm the scheduler and cause additional delays.
Spinlock implementations create more immediate resource waste. If three processes are spinning while waiting for a lock, and the holder gets preempted, those three processes continue consuming CPU cycles on their respective cores. In the worst case, this spinning can saturate available CPU capacity, making the system less responsive and potentially delaying the lock holder's return to execution.
The impact extends beyond the immediate lock contention. When processes are delayed by lock waits, they might miss their own scheduling deadlines, causing cascading delays throughout the application. A web server process that should respond to HTTP requests within milliseconds might be blocked for tens of milliseconds waiting for a database connection lock, leading to client timeouts and degraded user experience.
Memory pressure can also increase during extended lock waits. If processes are blocked while holding other resources like network connections, memory buffers, or file descriptors, these resources remain allocated longer than intended. This can lead to resource exhaustion and force the operating system to swap memory to disk, further degrading performance.
Multi-Server Distributed Challenges
Distributed systems amplify the scheduler preemption problem through network effects and coordination overhead. When a process on one server holds a distributed lock and gets preempted, processes on all other servers must wait. This transforms a local scheduling delay into a system-wide performance bottleneck.
Network-based lock coordination introduces additional latency layers. A process might need to communicate with a central lock service like etcd or Consul to acquire a lock. If that process gets preempted while holding the lock, other processes must continue polling the lock service or wait for lock release notifications. The network round-trip time for these operations typically ranges from hundreds of microseconds to several milliseconds, compounding the delay caused by scheduler preemption.
Consider a database connection pool shared across five application servers. Each server runs multiple processes that occasionally need to reconfigure the connection pool parameters. They use a Redis-based distributed lock to ensure mutual exclusion during reconfiguration. When a process on Server A acquires the lock and begins reconfiguration, processes on Servers B through E block, waiting for the lock release. If Server A's process gets preempted mid-reconfiguration, all five servers experience degraded performance as their processes remain blocked.
The problem becomes more complex with partial failures. If the lock-holding process gets preempted for an extended period, other servers might interpret this as a failure and attempt recovery actions. In systems using lease-based locks, the lock might expire while the holder is preempted, allowing another process to acquire it. When the original holder resumes execution, it might continue working under the assumption that it still holds the lock, leading to race conditions and data corruption.
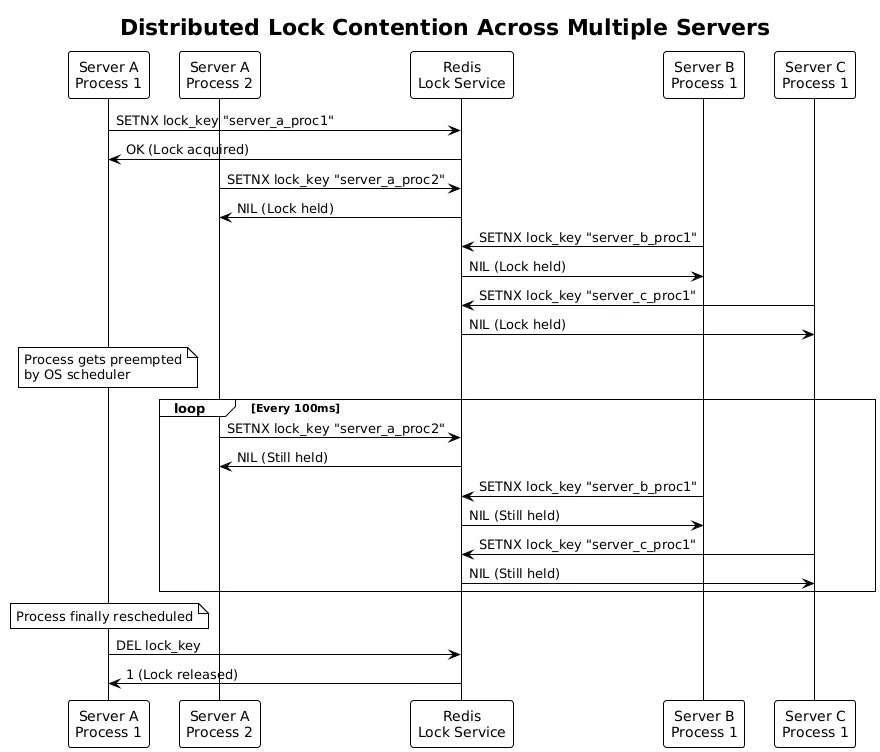
Worst-Case Scenarios and System Degradation
Several factors can transform routine scheduler preemption into severe system degradation. High system load creates the most common worst-case scenario. When CPU utilization approaches 100%, processes experience longer delays between preemption and rescheduling. A process that normally waits a few milliseconds to run again might wait hundreds of milliseconds or several seconds.
Priority inversion represents another critical failure mode. If a low-priority process holds a lock that high-priority processes need, the entire system can become unresponsive. The high-priority processes block waiting for the lock, while the low-priority holder might be starved of CPU time by medium-priority processes that don't need the lock. This scenario can effectively deadlock the system despite no circular dependencies in the locking logic.
Memory pressure exacerbates scheduling delays through swapping. When the system runs low on physical memory, the operating system starts swapping process memory to disk. If a lock-holding process gets swapped out, it might not be eligible for rescheduling until its memory pages are swapped back in. Disk I/O for swapping typically takes milliseconds or tens of milliseconds, during which all lock waiters remain blocked.
In distributed systems, network partitions can combine with scheduler preemption to create particularly problematic scenarios. If a process holds a distributed lock and then its server experiences network connectivity issues, other servers cannot determine whether the process crashed or is simply preempted. Some distributed lock implementations handle this through timeouts, but conservative timeout values (set to avoid premature lock release) can lead to extended delays.
Lock convoys represent a systemic degradation pattern that emerges from repeated scheduler preemption. When a lock holder gets preempted, multiple processes queue up waiting for the lock. When the holder finally releases the lock, all waiters wake up and compete intensely for the next acquisition. This competition can cause the new lock holder to be preempted more quickly due to increased system load, perpetuating the convoy effect.
The convoy effect is particularly damaging in systems with bursty workloads. During traffic spikes, more processes compete for locks, increasing the likelihood of preemption during critical sections. Each preemption event makes the system less responsive, which can trigger additional load as clients retry failed requests, creating a positive feedback loop toward system overload.
Mitigation Strategies and Best Practices
Reducing lock hold time represents the most effective mitigation strategy. Critical sections should contain only the minimum necessary work, with all preparatory computation moved outside the lock. Instead of acquiring a lock and then performing expensive operations like memory allocation, I/O, or complex calculations, processes should complete these operations first, then acquire the lock only for the final atomic updates.
This principle applies particularly well to data structure updates. Rather than holding a lock while searching through a list or tree structure, processes can perform the search without locking, then acquire the lock briefly to verify the search results are still valid and perform the actual modification. This approach reduces lock hold times from potentially milliseconds to microseconds.
Fine-grained locking strategies help reduce contention by allowing different processes to work on different resources simultaneously. Instead of using a single lock to protect an entire data structure, systems can use multiple locks for different sections or use lock-free data structures that rely on atomic operations. Hash tables, for example, can use per-bucket locks instead of a single global lock, dramatically reducing the probability that any given process will be blocked.
Reader-writer locks provide another refinement for scenarios where multiple processes need to read shared data but only occasional processes need to modify it. Multiple readers can proceed simultaneously, reducing contention. However, writer starvation becomes a concern if readers continuously arrive before writers can acquire exclusive access.
Lock-free and wait-free algorithms eliminate the preemption problem entirely by avoiding locks altogether. These approaches use atomic compare-and-swap operations to update shared data structures. While implementation complexity increases significantly, the performance benefits can be substantial in high-contention scenarios. Lock-free queues, stacks, and hash tables are available in most modern programming languages and runtime libraries.
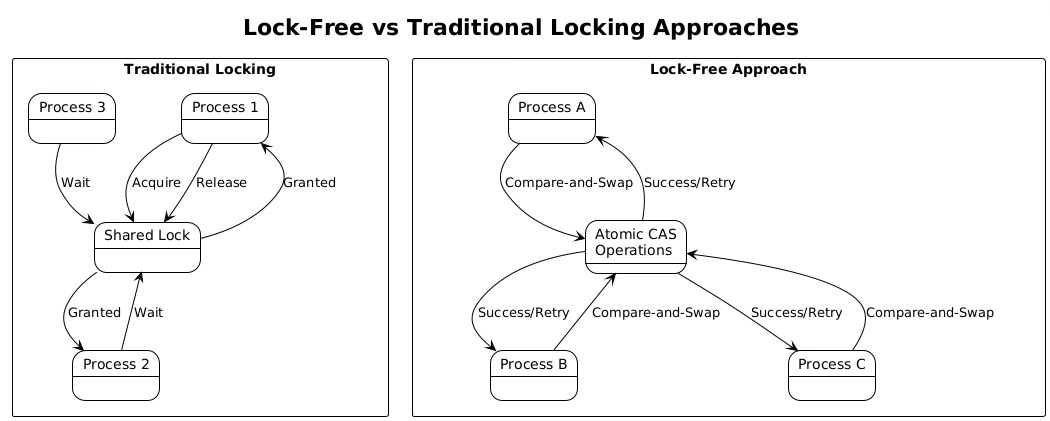
For scenarios where locks cannot be eliminated, hybrid spinning approaches can reduce the impact of scheduler preemption. Libraries like pthread in Linux implement adaptive mutexes that spin briefly before blocking. If the lock becomes available during the spin period, the waiting process can acquire it immediately without going through the scheduler. However, spin duration must be calibrated carefully; too much spinning wastes CPU cycles, while too little spinning provides no benefit.
Priority inheritance mechanisms help address priority inversion scenarios. When a high-priority process blocks on a lock held by a lower-priority process, priority inheritance temporarily elevates the holder's priority to match the highest waiting process. This ensures the holder gets scheduled promptly to release the lock. Linux futexes support priority inheritance, and real-time operating systems typically provide more comprehensive priority management.
In distributed systems, lease-based locks with careful timeout management can limit the impact of scheduler preemption. Instead of holding locks indefinitely, processes acquire time-limited leases that automatically expire. The lease duration must balance two competing concerns: short leases minimize the impact of preempted holders, but increase the risk of premature expiration when processes are legitimately taking longer to complete their work.
Implementing proper monitoring and observability helps identify preemption-related performance issues. Metrics should track lock acquisition times, hold durations, and queue depths. Histograms of these metrics reveal when scheduler preemption is causing problems. For example, if lock hold times show a bimodal distribution with some very short holds and others much longer, this often indicates preemption during critical sections.
Implementation Examples and Practical Guidance
Different programming languages and runtime environments provide various tools for managing the interaction between scheduling and locking. Java's ReentrantLock class includes tryLock methods with timeouts, allowing processes to avoid indefinite blocking. The java.util.concurrent package provides high-level constructs like Semaphore and CountDownLatch that handle many of the low-level details of coordination.
Python's threading module includes similar facilities, though the Global Interpreter Lock (GIL) creates additional complexity in multi-threaded Python applications. For CPU-bound work, Python multiprocessing often provides better performance than threading, but introduces additional complications for shared state management.
C and C++ provide lower-level control through POSIX threads (pthreads) and C++ standard library threading facilities. The std::mutex class supports various locking strategies, while std::atomic provides lock-free operations for simple data types. Memory ordering specifications in C++ atomic operations require careful consideration to ensure correctness across different CPU architectures.
Container orchestration platforms like Kubernetes can help mitigate some distributed locking issues through resource isolation and quality-of-service guarantees. By running lock-critical processes in guaranteed QoS pods with dedicated CPU resources, administrators can reduce the likelihood of preemption during critical sections. However, this approach requires careful resource planning and may not be cost-effective for all applications.
Database systems provide another perspective on handling concurrency and preemption. Most databases implement sophisticated lock managers that understand the relationships between different lock types and can make intelligent decisions about lock ordering and timeout handling. Application developers can often leverage database-level locking instead of implementing their own distributed locking mechanisms.
Message queues offer an alternative to shared-state concurrency that eliminates many preemption-related issues. Instead of using locks to coordinate access to shared resources, processes can communicate through asynchronous message passing. This approach naturally decouples processes and reduces the impact of scheduling delays, though it introduces different challenges around message ordering and delivery guarantees.
When implementing custom locking solutions, several design patterns help minimize preemption impact. The double-checked locking pattern, when implemented correctly, reduces the frequency of lock acquisition by performing an initial check outside the lock. However, this pattern requires careful attention to memory ordering and is notoriously difficult to implement correctly without deep understanding of the underlying memory model.
Monitoring and Performance Analysis
Effective monitoring strategies focus on metrics that reveal the hidden costs of scheduler preemption. Lock acquisition latency histograms show the distribution of wait times, with long tail latencies often indicating preemption issues. These metrics should be collected at high resolution (microsecond precision) to distinguish between normal operation and preemption-induced delays.
System-level monitoring complements application metrics by providing context about scheduler behavior. CPU utilization patterns, context switch rates, and run queue lengths help identify when system load contributes to locking problems. Tools like top, htop, and sar on Linux provide real-time visibility into these metrics.
For distributed systems, correlation analysis across servers helps identify system-wide patterns. If lock wait times increase simultaneously across all servers, this suggests a problem with the central lock service or the process holding the distributed lock. If delays appear on only one server, local scheduling or resource issues are more likely.
Profiling tools like perf on Linux can provide detailed insight into where processes spend their time. By sampling running processes at high frequency, perf can reveal how much time processes spend in different states: running, blocked on locks, or waiting to be scheduled. This information helps distinguish between different types of performance problems.
Application-level tracing provides the most detailed view of locking behavior. Distributed tracing frameworks like Jaeger or Zipkin can track requests across multiple services and servers, showing how lock contention affects end-to-end latency. Custom instrumentation around lock acquisition and release points helps build a complete picture of system behavior.
The insights gained from monitoring and profiling inform both immediate performance tuning and longer-term architectural decisions. Short-term fixes might involve adjusting process priorities, modifying lock timeout values, or redistributing workload across servers. Longer-term improvements could include redesigning critical sections to reduce hold times, adopting lock-free algorithms, or restructuring the application to reduce shared state dependencies.
Understanding the interplay between operating system scheduling and application-level locking represents a crucial skill for developers building high-performance distributed systems. While modern operating systems and programming languages provide sophisticated tools for managing concurrency, the fundamental tension between preemptive multitasking and mutual exclusion remains. By designing systems that minimize lock contention, reduce hold times, and gracefully handle scheduling delays, developers can build applications that maintain high performance even under challenging conditions.
The five-server scenario described at the beginning illustrates how local scheduling decisions can have global performance implications. As distributed systems continue to grow in complexity and scale, managing these interactions becomes increasingly important for delivering responsive, reliable applications. The strategies and techniques outlined here provide a foundation for building systems that perform well despite the inherent unpredictability of preemptive scheduling.