


Routing Decision Process: Understanding How Packets Navigate From Host to Gateway
The Complete Journey of a Packet: From Application to Destination

When you type a URL into your browser or send data across a network, your computer faces an immediate decision. Should this packet stay on the local network, or does it need to travel through a gateway to reach its destination? This fundamental routing decision happens millions of times per second on every networked device, yet most users never realize the complex logic operating beneath the surface.
The journey begins the moment an application generates data destined for another host. Before any packet can leave your computer, the operating system kernel must determine the best path for that data to travel. This process involves consulting routing tables, resolving hardware addresses, selecting network interfaces, and preparing packets for transmission across the local network segment.
Local vs Remote Destination Analysis
Every packet's journey starts with a critical question that your operating system must answer within microseconds. Is the destination address reachable directly on the local network, or must the packet traverse through a router to reach a remote network? This determination forms the foundation of all routing decisions.
Your computer performs this analysis by examining the destination IP address against its own network configuration. The process begins with a subnet mask comparison. When your network interface receives an IP address configuration, whether through DHCP or manual assignment, it also receives a subnet mask that defines the boundaries of your local network segment.
Let's examine this process in action on a Linux system:
ip addr show dev eth0
# Output shows:
# 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP
# inet 192.168.1.100/24 brd 192.168.1.255 scope global eth0The "/24" notation indicates that the first 24 bits of the IP address identify the network portion. Your system performs a bitwise AND operation between the destination address and your subnet mask. If the result matches your own network address, the destination is local. Otherwise, it's remote.
Consider a practical example. Your computer has IP address 192.168.1.100 with a subnet mask of 255.255.255.0. When sending to 192.168.1.150, the system calculates:
Destination: 192.168.1.150 AND 255.255.255.0 = 192.168.1.0 Source network: 192.168.1.100 AND 255.255.255.0 = 192.168.1.0
Since both results match, the destination is on the local network. The system can attempt direct communication without involving a router.
However, if the destination is 8.8.8.8 (Google's DNS server), the calculation yields: 8.8.8.8 AND 255.255.255.0 = 8.8.8.0
This doesn't match the local network address of 192.168.1.0, so the packet must be sent to a gateway router for forwarding.
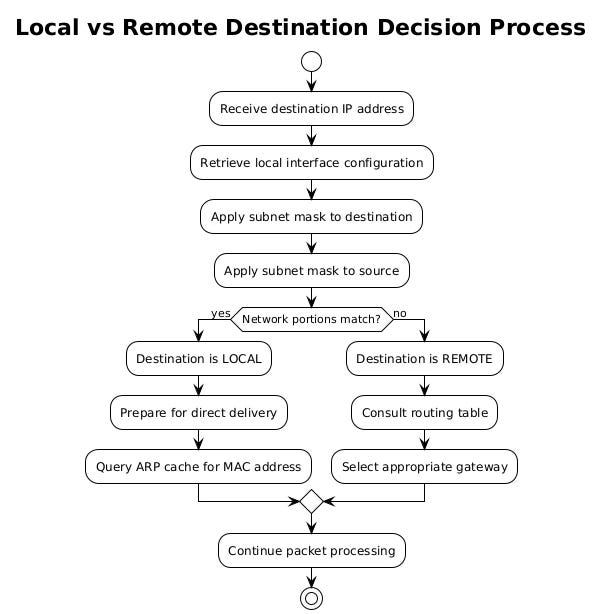
The kernel maintains this logic in its networking stack, implemented differently across operating systems but following the same fundamental principles. In Linux, the netfilter framework handles these decisions, while Windows uses the Windows Filtering Platform. Both systems optimize this process through caching mechanisms that remember recent routing decisions.
Routing Table Consultation
When a packet needs to reach a remote destination, your operating system consults its routing table, a database that maps network destinations to next-hop addresses or interfaces. This table serves as the roadmap for all non-local traffic, containing entries that specify where packets should be sent based on their destination addresses.
The routing table exists in kernel memory and gets updated through various mechanisms. Static routes are configured manually by administrators, while dynamic routes come from routing protocols or network configuration services like DHCP. Each entry in the table contains several key pieces of information: the destination network, the subnet mask or prefix length, the gateway address, the interface to use, and a metric indicating the preference or cost of the route.
View your system's routing table with:
ip route show
# Sample output:
# default via 192.168.1.1 dev eth0 proto dhcp metric 100
# 10.0.0.0/8 via 192.168.1.254 dev eth0 metric 50
# 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100
# 192.168.10.0/24 via 192.168.1.2 dev eth0Each line represents a route. The default route (0.0.0.0/0) acts as a catch-all for destinations not matching any other entry. More specific routes take precedence over less specific ones, following the Longest Prefix Match algorithm.
The kernel maintains multiple routing tables for different purposes. The main table handles regular unicast traffic, while other tables might handle multicast routing, policy-based routing, or traffic from specific sources. Linux systems can have up to 255 different routing tables, each identified by a number or name.
# View all routing tables
ip rule list
# Output:
# 0: from all lookup local
# 32766: from all lookup main
# 32767: from all lookup default
# Examine a specific table
ip route show table mainThe routing decision process evaluates each packet against these tables in a specific order determined by routing rules. These rules can match on various packet attributes including source address, destination address, incoming interface, packet marking, and even user ID of the process that generated the packet.
Modern operating systems implement sophisticated route caching mechanisms to accelerate the lookup process. Instead of searching through the entire routing table for every packet, the kernel maintains a cache of recently used routes. This cache, often implemented as a hash table or trie structure, provides O(1) or O(log n) lookup times for frequently accessed destinations.
Route Lookup Algorithms (Longest Prefix Match)
The Longest Prefix Match (LPM) algorithm forms the cornerstone of IP routing decisions. When multiple routes could potentially match a destination address, LPM ensures that the most specific route wins. This algorithm compares the destination address against each route's network prefix, selecting the entry with the longest matching prefix.
Understanding LPM requires examining how routers and operating systems organize routing information internally. Rather than storing routes as a simple list, modern systems use advanced data structures like Patricia tries (radix trees) or compressed tries that enable efficient prefix matching. These structures allow the system to traverse the routing table in logarithmic time relative to the number of routes.
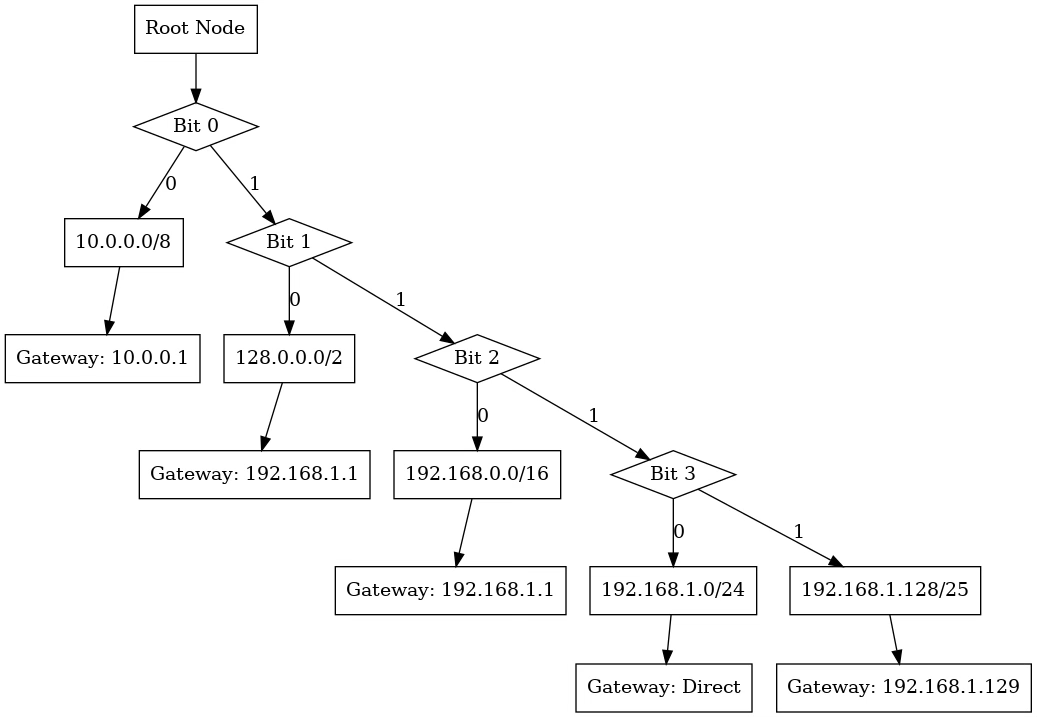
Consider a packet destined for 192.168.1.150. The routing table might contain:
0.0.0.0/0 via 192.168.1.1 (default route, matches everything)
192.168.0.0/16 via 192.168.1.254 (matches 192.168.x.x)
192.168.1.0/24 directly connected (matches 192.168.1.x)
192.168.1.128/25 via 192.168.1.129 (matches 192.168.1.128-255)
All four routes technically match the destination, but the /25 route has the longest prefix (25 bits) and therefore wins. The packet will be sent to gateway 192.168.1.129.
Linux implements LPM through the FIB (Forwarding Information Base) trie structure:
# Examine the kernel's FIB trie structure
cat /proc/net/fib_trie
# This shows the internal organization of routes as a trie
# Test route lookup for a specific destination
ip route get 8.8.8.8
# Output: 8.8.8.8 via 192.168.1.1 dev eth0 src 192.168.1.100 uid 1000The algorithm's efficiency becomes crucial in core routers handling millions of packets per second. Hardware routers often implement LPM in specialized chips called TCAMs (Ternary Content-Addressable Memory) that can perform prefix matching in a single clock cycle. Software routers and operating systems rely on optimized trie implementations that minimize memory access and cache misses.
Default Gateway Selection
The default gateway represents the router of last resort, the destination for all packets that don't match any specific route in the routing table. While conceptually simple, default gateway selection involves several considerations that affect network performance and reliability.
Most systems receive their default gateway configuration through DHCP, which provides not just an IP address but also the gateway address, DNS servers, and other network parameters. The DHCP server typically advertises the gateway closest to the client, but in complex networks, multiple gateways might be available.
When multiple default gateways exist, the system must choose between them. This decision relies on metrics, numerical values that indicate route preference. Lower metrics indicate preferred routes. The metric might represent hop count, bandwidth, latency, or an administrative preference.
# Add multiple default gateways with different metrics
sudo ip route add default via 192.168.1.1 metric 100
sudo ip route add default via 192.168.1.2 metric 200
# The kernel will prefer the route with metric 100
ip route show default
# default via 192.168.1.1 dev eth0 metric 100
# default via 192.168.1.2 dev eth0 metric 200Advanced configurations might use different gateways for different types of traffic through policy-based routing. For example, web traffic might use one gateway while VoIP traffic uses another for quality of service reasons.
Multiple Routing Table Support
Modern operating systems support multiple routing tables to enable sophisticated traffic management policies. Each table can contain a completely different set of routes, and policy rules determine which table to consult for each packet. This capability enables virtual routing domains, source-based routing, and quality of service implementations.
Policy routing rules are evaluated in priority order, with lower numbers taking precedence. Each rule specifies match criteria and an action, typically selecting a routing table. The system evaluates rules until finding a match, then uses the specified table for route lookup.
# Create a custom routing table
echo "200 custom_table" >> /etc/iproute2/rt_tables
# Add routes to the custom table
sudo ip route add 10.0.0.0/8 via 192.168.1.254 table custom_table
sudo ip route add default via 192.168.1.253 table custom_table
# Create a rule to use this table for specific source addresses
sudo ip rule add from 192.168.1.150 table custom_table priority 100
# Verify the rule
ip rule show
# 100: from 192.168.1.150 lookup custom_tableThis architecture enables Virtual Routing and Forwarding (VRF), where different network namespaces or containers can have completely isolated routing domains. Each VRF maintains its own routing table, preventing route leaking between different security domains or customers in multi-tenant environments.
ARP (Address Resolution Protocol) Process
Once the routing decision determines the next-hop IP address, whether that's the final destination for local delivery or a gateway for remote delivery, the system needs to discover the corresponding MAC address. Ethernet and most other link-layer protocols require hardware addresses for frame delivery. ARP bridges this gap between logical IP addresses and physical MAC addresses.
The ARP process begins with a cache lookup. Operating systems maintain an ARP cache to avoid repeatedly resolving the same addresses. This cache stores recent IP-to-MAC mappings with timeout values to ensure freshness.
# View the ARP cache
ip neigh show
# 192.168.1.1 dev eth0 lladdr 00:11:22:33:44:55 REACHABLE
# 192.168.1.50 dev eth0 lladdr 00:aa:bb:cc:dd:ee STALE
# 192.168.1.75 dev eth0 lladdr 00:12:34:56:78:90 DELAYCache entries progress through different states. REACHABLE indicates a valid, recently confirmed entry. STALE means the entry timeout expired but it's still usable. DELAY indicates the system sent a packet and awaits confirmation. PROBE means the system is actively trying to reconfirm the entry.
When no cache entry exists, the system must perform ARP discovery. It broadcasts an ARP request packet asking "Who has IP address X.X.X.X? Tell Y.Y.Y.Y" where Y.Y.Y.Y is the sender's IP. This broadcast reaches all hosts on the local network segment.
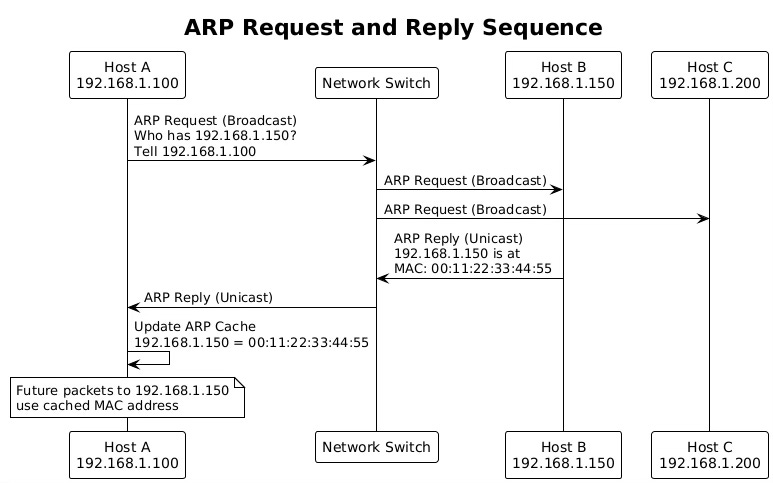
ARP Cache Lookup
The ARP cache serves as a performance optimization, eliminating the need for broadcast discovery on every packet transmission. The kernel implements this cache as a hash table indexed by IP address, providing constant-time lookups for cached entries.
Cache management involves several timers and thresholds. Each entry has a reachability timer that tracks when the entry was last confirmed valid. Once this timer expires, the entry transitions to STALE state but remains usable. If traffic needs to reach that destination again, the kernel sends a unicast ARP request to reconfirm the mapping.
# Modify ARP cache parameters
# Set base reachable time (in milliseconds)
sudo sysctl -w net.ipv4.neigh.default.base_reachable_time_ms=30000
# Set garbage collection intervals
sudo sysctl -w net.ipv4.neigh.default.gc_interval=30
sudo sysctl -w net.ipv4.neigh.default.gc_stale_time=60
# View all ARP-related parameters
sysctl -a | grep neigh.defaultThe cache implements garbage collection to prevent unbounded growth. Entries in FAILED state get removed quickly, while STALE entries might persist longer if memory permits. The kernel enforces both soft and hard limits on cache size, evicting least-recently-used entries when necessary.
ARP Request/Reply Mechanism
ARP requests use a specific packet format encapsulated directly in Ethernet frames. The ARP header contains fields for hardware type, protocol type, hardware address length, protocol address length, operation code, and the sender/target hardware and protocol addresses.
When broadcasting an ARP request, the sender includes its own MAC and IP addresses, allowing recipients to update their caches opportunistically. This gratuitous information reduces future ARP traffic since recipients learn the sender's mapping without sending their own requests.
The broadcast nature of ARP introduces security vulnerabilities. ARP spoofing attacks involve sending false ARP replies to redirect traffic through an attacker's machine. Modern networks implement Dynamic ARP Inspection and other security measures to validate ARP packets against trusted bindings.
Neighbor Discovery in IPv6
IPv6 replaces ARP with the Neighbor Discovery Protocol (NDP), part of ICMPv6. While serving the same address resolution purpose, NDP offers additional functionality including stateless address autoconfiguration, duplicate address detection, and router discovery.
NDP uses multicast instead of broadcast, reducing unnecessary processing on non-involved hosts. The solicited-node multicast address is computed from the target IP address, ensuring only hosts with matching addresses process the request.
# View IPv6 neighbors (equivalent to ARP cache)
ip -6 neigh show
# fe80::1 dev eth0 lladdr 00:11:22:33:44:55 router REACHABLE
# 2001:db8::100 dev eth0 lladdr 00:aa:bb:cc:dd:ee STALE
# Monitor NDP traffic
sudo tcpdump -i eth0 icmp6 and 'ip6[40] == 135 or ip6[40] == 136'NDP includes several message types:
Neighbor Solicitation (NS): Similar to ARP request
Neighbor Advertisement (NA): Similar to ARP reply
Router Solicitation (RS): Hosts request router information
Router Advertisement (RA): Routers announce their presence
Redirect: Routers inform hosts of better next-hop addresses
Network Interface Selection
Multi-homed hosts with multiple network interfaces face additional routing complexity. The system must select not just the next-hop address but also the appropriate interface for packet transmission. This decision affects both performance and reachability.
Interface selection follows routing table entries, where each route specifies an outgoing interface. However, when multiple interfaces could reach the same destination, the system considers interface metrics, administrative preferences, and link status.
# View interface statistics and status
ip -s link show
# Monitor interface selection for specific destinations
ip route get 8.8.8.8
# 8.8.8.8 via 192.168.1.1 dev eth0 src 192.168.1.100 uid 1000
# Force traffic through specific interface
sudo ip route add 10.0.0.0/8 dev eth1Source address selection becomes crucial for multi-homed hosts. The kernel must choose an appropriate source IP address that's routable back to the host through the selected interface. Incorrect source address selection can cause asymmetric routing or packet drops due to reverse path filtering.
Multi-homed Host Considerations
Multi-homed configurations introduce complexity in routing decisions. Each interface might connect to different networks with varying performance characteristics, security policies, and reachability. The operating system must intelligently distribute traffic across available interfaces while maintaining connection stability.
Linux implements source address selection through a defined algorithm considering address scope, deprecated addresses, and preference values. The selection aims to match the source and destination address scopes and prefer non-deprecated, permanent addresses over temporary ones.
Policy routing becomes essential in multi-homed environments. Different applications or users might need different network paths. For example, production traffic might use a dedicated high-bandwidth interface while management traffic uses a separate network for security isolation.
Interface Metrics and Preferences
Interface metrics influence routing decisions when multiple paths exist to the same destination. Lower metrics indicate preferred paths, but the interpretation varies between operating systems. Linux treats metrics as additional routing criteria, while Windows uses them for automatic metric calculation based on interface speed.
# Set interface metric
sudo ip route add default via 192.168.1.1 dev eth0 metric 100
sudo ip route add default via 10.0.0.1 dev eth1 metric 200
# Adjust interface priority
sudo ip link set dev eth0 priority 10Dynamic metrics adjust based on link conditions. Some systems monitor packet loss, latency, and bandwidth utilization to automatically adjust route preferences. This adaptive behavior improves resilience but can cause routing instability if not properly dampened.
Quality of Service (QoS) Marking
Before packets leave the host, the operating system can apply Quality of Service markings that influence treatment throughout the network path. These markings don't affect local routing decisions but prepare packets for differentiated handling by routers and switches.
The Differentiated Services Code Point (DSCP) field in the IP header carries QoS information. Applications or administrators can set DSCP values to indicate traffic priority, affecting queuing, scheduling, and drop probability in network devices.
# Mark packets with DSCP values using iptables
sudo iptables -t mangle -A OUTPUT -p tcp --dport 443 -j DSCP --set-dscp 46
# EF (Expedited Forwarding) for HTTPS traffic
# View current marking rules
sudo iptables -t mangle -L -v -nDSCP Field Configuration
DSCP values follow standardized Per-Hop Behaviors (PHBs) that define traffic treatment. Expedited Forwarding (EF) provides low-latency, low-jitter service for real-time traffic. Assured Forwarding (AF) offers multiple classes with different drop probabilities. Best Effort receives no special treatment.
The kernel's traffic control subsystem can classify and mark packets based on various criteria including application, user, destination, or packet characteristics. This marking happens after routing decisions but before interface queuing.
Traffic Classification
Traffic classification identifies packet flows for appropriate QoS treatment. Classification can examine multiple packet attributes:
Transport protocol and port numbers
Application layer protocols through deep packet inspection
Source and destination addresses
Packet size and rate patterns
Process or user ID that generated the traffic
Linux netfilter provides comprehensive classification capabilities:
# Create traffic classes
sudo tc qdisc add dev eth0 root handle 1: htb
sudo tc class add dev eth0 parent 1: classid 1:10 htb rate 100mbit
sudo tc class add dev eth0 parent 1: classid 1:20 htb rate 50mbit
# Classify traffic into classes
sudo tc filter add dev eth0 protocol ip parent 1: prio 1 u32 \
match ip dport 80 0xffff flowid 1:10Local Network Transmission Preparation
After routing decisions, ARP resolution, and QoS marking, the kernel prepares packets for transmission on the local network segment. This preparation involves final header construction, checksum calculation, and queuing for the network interface card.
The kernel maintains transmit queues for each network interface. These queues buffer packets awaiting transmission, smoothing traffic bursts and coordinating access to the physical medium. Queue disciplines (qdiscs) control packet scheduling and potentially implement traffic shaping or prioritization.
Segmentation offload features defer packet fragmentation to the network interface card. TCP Segmentation Offload (TSO) allows the kernel to pass large TCP segments to the NIC, which splits them into MTU-sized packets. This reduces CPU overhead and improves throughput.
# View interface queue statistics
tc -s qdisc show dev eth0
# Configure transmit queue length
sudo ip link set dev eth0 txqueuelen 2000
# Check offload settings
ethtool -k eth0 | grep segmentationError Handling and ICMP Generation
Routing failures trigger ICMP error messages that inform the sender about problems. When no route exists to a destination, the kernel generates an ICMP Destination Unreachable message with code "Network Unreachable" or "Host Unreachable" depending on the failure type.
The kernel rate-limits ICMP generation to prevent denial-of-service attacks. Each error type has separate rate limits, and the system tracks recent ICMP messages to avoid flooding. Administrators can tune these limits based on network requirements.
# View ICMP rate limits
sysctl net.ipv4.icmp_ratelimit
sysctl net.ipv4.icmp_ratemask
# Monitor ICMP errors
sudo tcpdump -i eth0 icmpPacket Too Big errors deserve special attention. When a packet exceeds the next-hop MTU and has the Don't Fragment bit set, the router must drop the packet and send an ICMP error. This mechanism enables Path MTU Discovery, allowing hosts to determine the maximum packet size for a path.
The routing subsystem also handles ICMP redirects, messages from routers indicating better paths to destinations. While processing redirects, the kernel validates their authenticity to prevent malicious route injection. Modern systems often disable redirect processing for security reasons.
Error handling extends beyond ICMP generation. The kernel maintains statistics about routing failures, invalid addresses, and other anomalies. These counters help administrators diagnose network problems and monitor system health. The routing decision process, from destination analysis through error handling, forms the critical foundation for all network communication, executing millions of times per second with microsecond precision.