
Storage Wars: Object vs Block vs File Systems Under the Hood
From file descriptors and inodes to REST APIs and eventual consistency—understanding what happens when your code hits storage

When you're designing distributed systems or optimizing database performance, you'll inevitably find yourself wrestling with storage choices. The difference between object, block, and file storage isn't just academic—it fundamentally shapes how your application interacts with the kernel, how data flows through the system, and where your performance bottlenecks will emerge.
I've spent countless hours debugging I/O performance issues, and the root cause often traces back to a mismatch between storage type and use case. A database trying to achieve microsecond latencies through file storage APIs, or an analytics pipeline overwhelming block storage with small random reads—these architectural decisions have real consequences that ripple through your entire stack.
Understanding storage at the kernel level isn't just useful for systems programming. Modern cloud architectures abstract away many details, but when things go wrong—and they will—you need to understand what's happening beneath the API calls. Whether you're troubleshooting why your S3 uploads are timing out, why your database is experiencing unexpected latency spikes, or why your file system is fragmenting, the answers lie in how these storage systems work at the lowest levels.
Storage Fundamentals: More Than Just APIs
Most engineers interact with storage through high-level APIs—open(), read(), write() for files, or REST calls for object storage. But these abstractions hide dramatically different underlying mechanisms. File storage gives you POSIX semantics with inodes and file descriptors. Block storage provides raw, unstructured access to storage devices through kernel block layers. Object storage throws away traditional file system concepts entirely, embracing eventual consistency and flat namespaces.
Each approach makes different tradeoffs in consistency, performance, and scalability. File storage prioritizes POSIX compliance and hierarchical organization. Block storage optimizes for raw performance and gives applications complete control over data layout. Object storage scales horizontally by sacrificing some consistency guarantees and eliminating file system overhead.
The choice isn't just about features—it's about how data flows through different kernel subsystems, how memory is managed, and how I/O operations are scheduled and executed.
File Storage: The POSIX Heritage
File storage feels familiar because it mirrors how we think about organizing documents—hierarchical directories, named files, and familiar operations like reading and writing. But underneath this familiar interface lies a sophisticated kernel subsystem that manages file descriptors, inodes, and complex interactions with storage devices.
File Descriptors: Your Handle to the Kernel
Every file operation begins with a file descriptor—a small integer that serves as your process's handle to a kernel data structure. When you call open(), the kernel allocates a struct file and returns a file descriptor that indexes into your process's file descriptor table.
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main() {
int fd = open("/tmp/test.txt", O_RDWR | O_CREAT, 0644);
if (fd == -1) {
perror("open failed");
return 1;
}
char buffer[1024];
ssize_t bytes_read = read(fd, buffer, sizeof(buffer));
// The fd is now associated with kernel structures
// that track file position, access mode, and inode reference
close(fd);
return 0;
}The file descriptor lifecycle involves several kernel data structures. The struct file contains the current file position, access flags, and a reference to the inode. The inode itself contains file metadata and pointers to data blocks on storage devices.
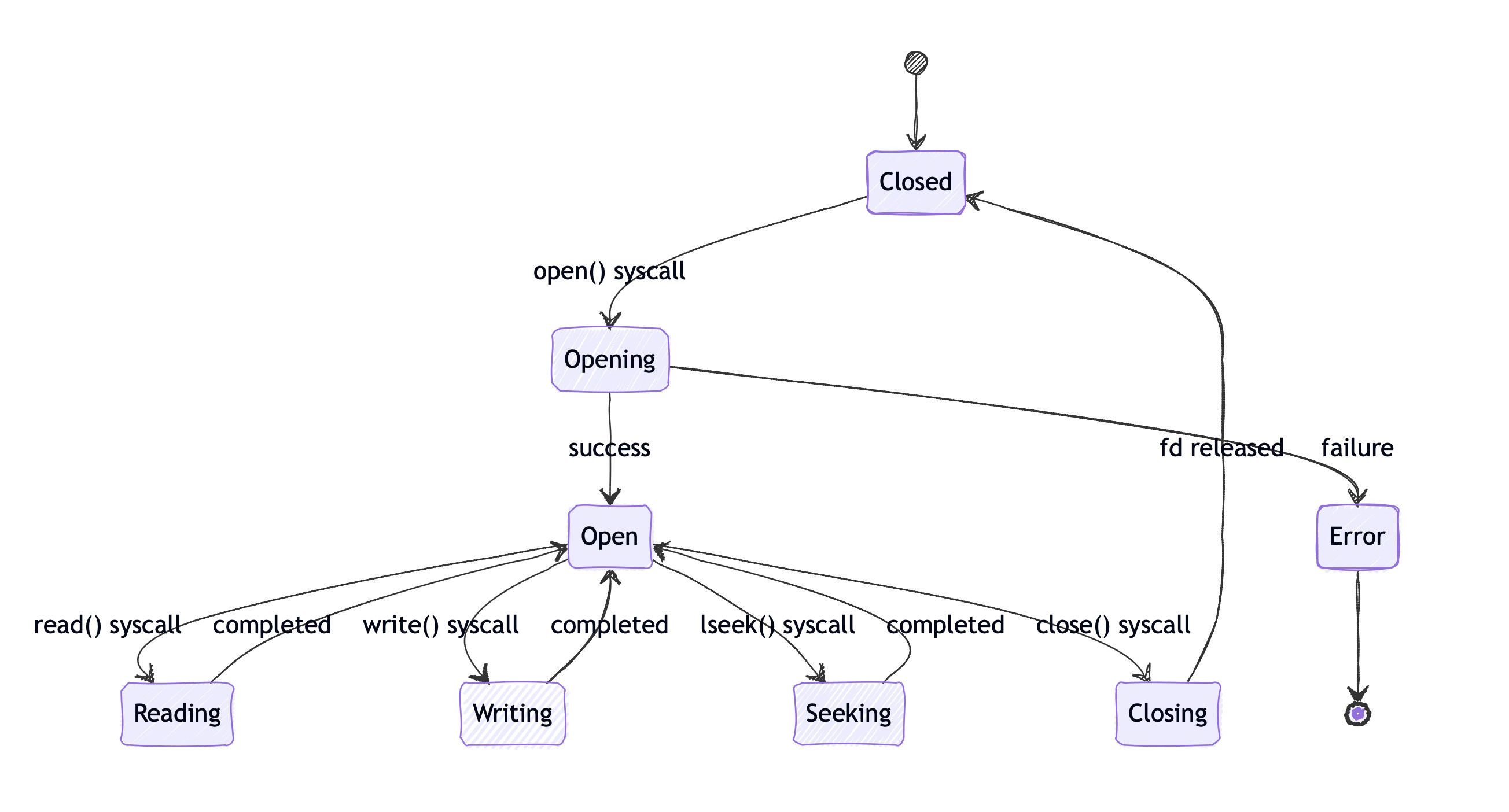
Above diagram shows how file descriptors transition through their lifecycle. Each transition involves kernel code that validates permissions, updates data structures, and potentially triggers I/O operations to storage devices.
Inodes: The File System's Database Records
Think of an inode as a database record that describes everything about a file except its name and data. The inode contains file size, permissions, timestamps, and—most importantly for performance—the mapping from logical file offsets to physical storage blocks.
struct inode {
umode_t i_mode; // File type and permissions
uid_t i_uid; // Owner user ID
gid_t i_gid; // Owner group ID
loff_t i_size; // File size in bytes
struct timespec i_atime; // Access time
struct timespec i_mtime; // Modification time
struct timespec i_ctime; // Change time
// Block mapping - this is where performance happens
union {
struct ext4_inode_info ext4_i;
struct xfs_inode xfs_i;
// ... other file system specific data
} u;
};The block mapping portion varies dramatically between file systems. ext4 uses extents—contiguous ranges of blocks—while older systems like ext2 used direct and indirect block pointers. This choice affects everything from file fragmentation to maximum file sizes.
When you read from a file, the kernel uses the inode's block mapping to translate your logical offset into physical storage locations. For large files, this translation can involve multiple levels of indirection, each requiring additional I/O operations.
The Virtual File System Layer
The VFS (Virtual File System) sits between your syscalls and the actual file system implementation. It provides a common interface that allows the same read() and write() calls to work with ext4, XFS, NFS, or even pseudo-file systems like /proc.
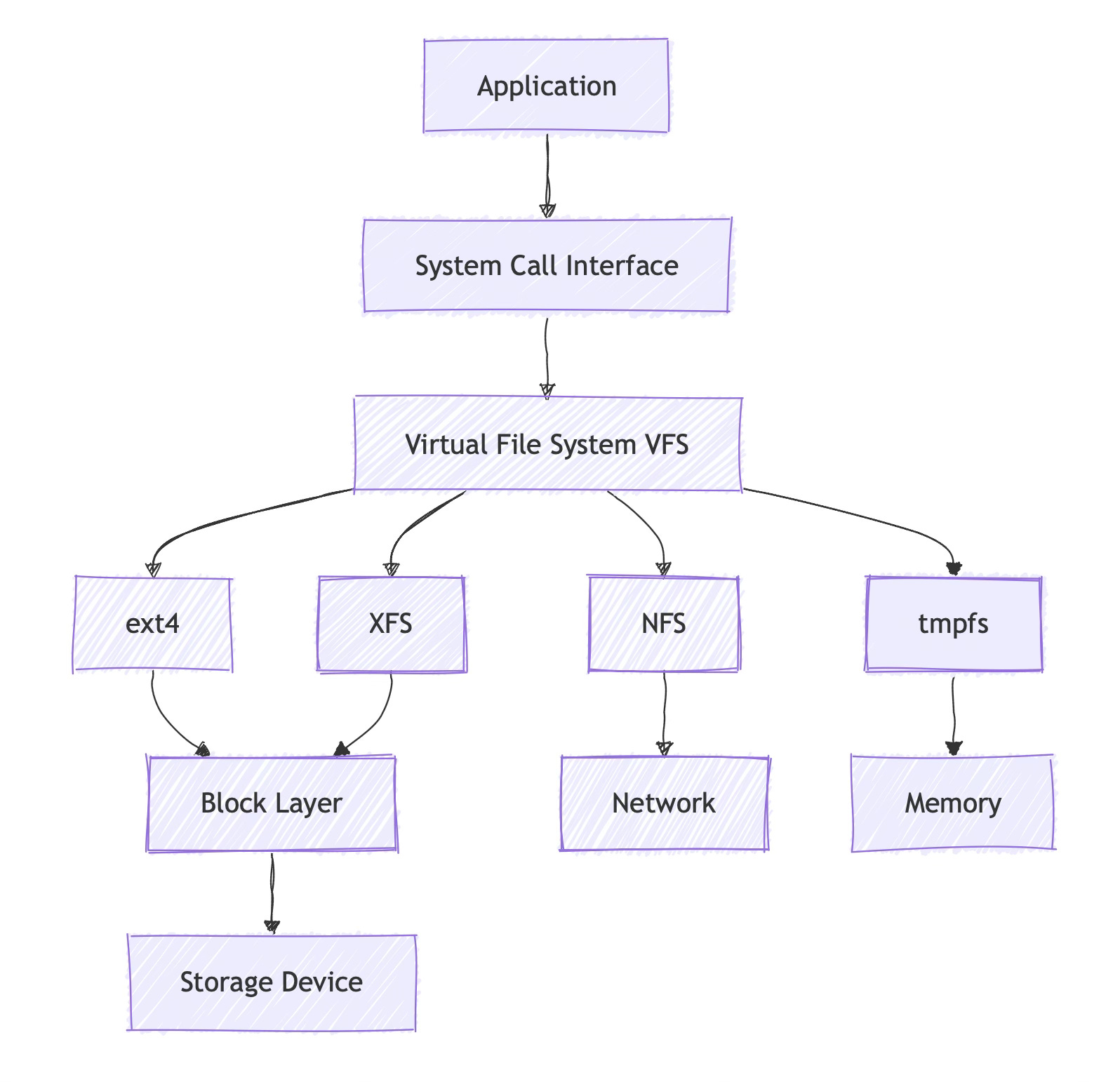
This layered architecture means that file I/O performance depends on multiple components. A slow read() call might be bottlenecked at the storage device, the file system's extent allocation, or even network latency if you're using NFS without realizing it.
File System Journaling and Consistency
Modern file systems like ext4 and XFS use journaling to maintain consistency after crashes. When you write data, the file system often writes to a journal first, then updates the actual data blocks and metadata. This double-write can significantly impact performance, especially for workloads with many small writes.
The fsync() syscall forces the kernel to flush dirty pages and journal entries to persistent storage. For applications that need durability guarantees—like databases—understanding when and how to use fsync() is crucial for both performance and correctness.
// Force dirty data and metadata to storage
int result = fsync(fd);
if (result == -1) {
perror("fsync failed");
// Data may not be durable!
}I remember debugging a database performance issue where fsync() calls were taking hundreds of milliseconds. The problem wasn't the storage device—it was the file system's journal configuration forcing synchronous writes for metadata updates.
Block Storage: Raw Performance
Block storage strips away file system abstractions and gives applications direct access to storage devices. Instead of files and directories, you work with fixed-size blocks identified by their logical block address (LBA). This approach eliminates file system overhead but shifts the burden of data organization to the application.
Block Devices and the I/O Stack
In Linux, block devices appear as special files in /dev—/dev/sda1, /dev/nvme0n1, or /dev/xvdf in cloud environments. But these aren't regular files. They're interfaces to kernel block device drivers that translate I/O requests into hardware-specific commands
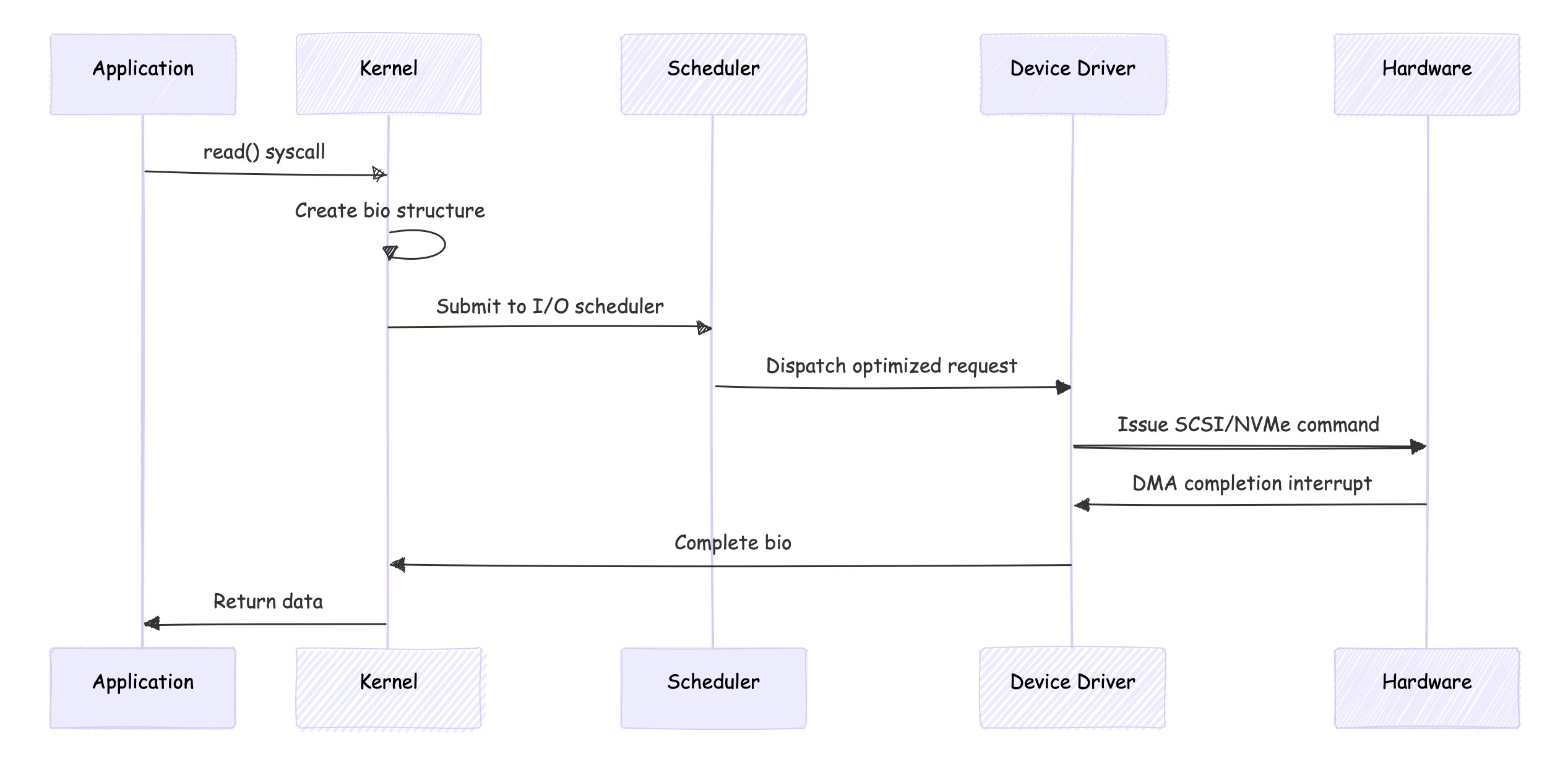
The kernel's block layer aggregates and optimizes I/O requests before sending them to storage devices. Multiple small reads might be combined into larger requests, or requests might be reordered to minimize disk head movement on rotating storage.
Block I/O Structures
When you read from a block device, the kernel creates a bio (block I/O) structure that describes the operation. This structure contains the target device, starting block address, length, and memory pages for the data.
struct bio {
struct block_device *bi_bdev; // Target block device
sector_t bi_sector; // Starting sector
unsigned int bi_size; // Size in bytes
unsigned short bi_vcnt; // Number of bio_vec entries
struct bio_vec *bi_io_vec; // Array of memory segments
// ... additional fields for completion, error handling
};The bio_vec structures point to physical memory pages where data will be read or written. This zero-copy approach means that data can flow directly between storage devices and application memory without additional copying in kernel space.
I/O Scheduling
The kernel's I/O scheduler decides when and in what order to dispatch block requests to storage devices. Different schedulers optimize for different workloads:
noop: Simple FIFO queue, best for fast storage like NVMe SSDs
deadline: Ensures no request is starved, good for mixed workloads
cfq (Completely Fair Queuing): Attempts fairness between processes
You can check and change the scheduler for a block device:
# Check current scheduler
cat /sys/block/sda/queue/scheduler
# Change to deadline scheduler
echo deadline > /sys/block/sda/queue/schedulerFor high-performance applications, choosing the right I/O scheduler can significantly impact latency and throughput. I've seen database performance improve by 30% just by switching from cfq to deadline on SSD storage.
Direct I/O and O_DIRECT
Applications can bypass the kernel's page cache using the O_DIRECT flag with open(). This eliminates double-buffering and gives applications more control over I/O timing, but requires careful alignment of I/O operations to block boundaries.
int fd = open("/dev/sdb1", O_RDWR | O_DIRECT);
if (fd == -1) {
perror("Failed to open with O_DIRECT");
return 1;
}
// Must align to block size (usually 512 bytes or 4KB)
void *buffer;
posix_memalign(&buffer, 4096, 4096);
ssize_t result = pread(fd, buffer, 4096, 0);Databases like PostgreSQL and MySQL use O_DIRECT for data files to avoid cache pollution and to have predictable I/O performance. But O_DIRECT isn't always faster—it depends on your access patterns and whether the kernel's read-ahead and caching algorithms help or hurt your workload.
Object Storage: Embracing Distribution
Object storage abandons traditional file system concepts in favor of a flat namespace and REST APIs. Instead of directories and files, you have buckets and objects identified by keys. This simplification enables massive horizontal scaling but changes how applications must think about data organization and consistency.
The Key-Value Model
In object storage, everything is identified by a key—a string that uniquely identifies an object within a bucket. There's no hierarchical namespace, though applications can simulate directories by using key prefixes like logs/2024/01/15/app.log.
import boto3
s3 = boto3.client('s3')
# PUT object
s3.put_object(
Bucket='my-bucket',
Key='data/metrics/2024-01-15.json',
Body=json.dumps(metrics_data)
)
# GET object
response = s3.get_object(
Bucket='my-bucket',
Key='data/metrics/2024-01-15.json'
)
data = response['Body'].read()This approach eliminates many file system bottlenecks. There's no single metadata server that needs to track directory structures, no inode allocation, and no file system journal to maintain consistency.
REST APIs and HTTP Semantics
Object storage systems expose REST APIs over HTTP, which means each operation maps to standard HTTP methods. This has profound implications for how operations are processed and what consistency guarantees you can expect.
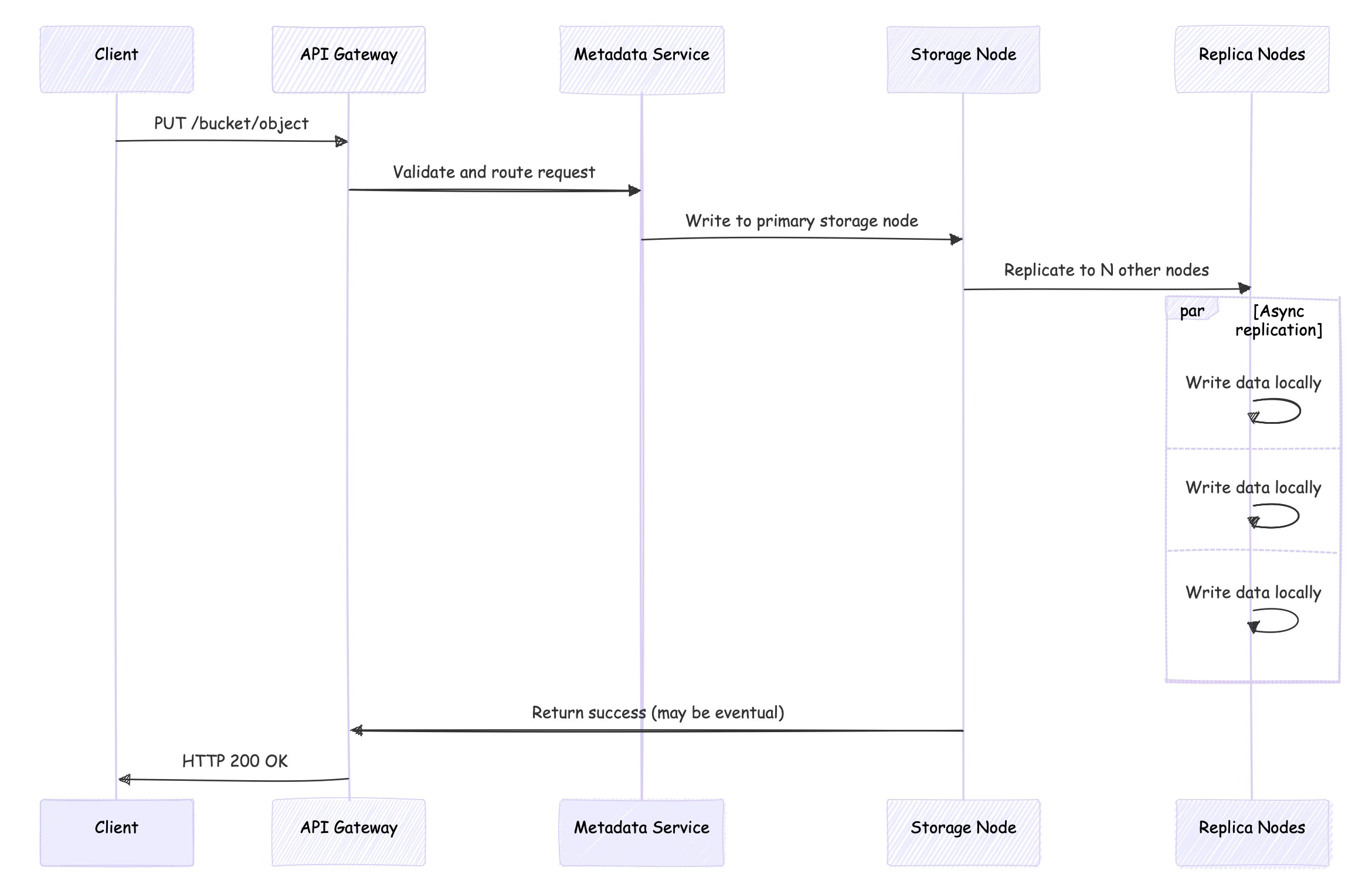
HTTP is stateless, which means each request is independent. There's no equivalent to file descriptors that maintain state between operations. This eliminates some complexity but also means that operations like appending to an object require reading the entire object, modifying it, and writing it back.
Eventual Consistency
Most object storage systems prioritize availability and partition tolerance over immediate consistency. When you PUT an object, it might take time to replicate to all storage nodes. During this window, different GET requests might return different versions of the object or even "object not found" errors.
Amazon S3 provides "read-after-write consistency" for new objects but only "eventual consistency" for updates. This means:
# This will work consistently
s3.put_object(Bucket='bucket', Key='new-key', Body=data)
response = s3.get_object(Bucket='bucket', Key='new-key') # Will succeed
# This might not work immediately
s3.put_object(Bucket='bucket', Key='existing-key', Body=updated_data)
response = s3.get_object(Bucket='bucket', Key='existing-key') # Might return old dataApplications built for object storage need to handle these consistency edge cases gracefully. Retry logic, versioning, and careful sequencing of operations become essential.
Metadata and Custom Headers
Unlike file systems where metadata is stored in inodes, object storage systems often allow arbitrary metadata to be associated with objects through HTTP headers. This metadata travels with the object and can be retrieved without reading the object data itself.
# Store custom metadata
s3.put_object(
Bucket='bucket',
Key='document.pdf',
Body=pdf_data,
Metadata={
'author': 'john.doe',
'department': 'engineering',
'classification': 'internal'
}
)
# Retrieve only metadata
response = s3.head_object(Bucket='bucket', Key='document.pdf')
metadata = response.get('Metadata', {})This flexibility allows applications to store rich metadata without the constraints of traditional file system attributes. But it also means that metadata queries can become expensive if they require scanning many objects.
Performance Characteristics and Trade-offs
The architectural differences between storage types create distinct performance profiles. Understanding these characteristics helps you choose the right storage for your workload and optimize your application's I/O patterns.
Latency Patterns
File storage latency depends heavily on whether data is cached in memory. Cache hits can complete in microseconds, while cache misses require disk I/O that takes milliseconds. The kernel's page cache and read-ahead algorithms try to keep frequently accessed data in memory, but this introduces variability in response times.
Block storage provides more predictable latency because applications control caching behavior. With O_DIRECT, every read goes to storage, eliminating the performance cliff when data isn't cached. But you lose the benefits of kernel optimizations like read-ahead and write coalescing.
Object storage typically has higher base latency due to HTTP overhead and network round-trips. Even operations that hit cache often take single-digit milliseconds due to the REST API processing. But object storage scales horizontally, so aggregate throughput can be enormous.
Throughput and Scalability
File systems have inherent scalability limits. A single file system can only grow so large before metadata operations become bottlenecks. Even distributed file systems like Lustre or GlusterFS have coordination overhead that limits scaling.
Block storage throughput is limited by the underlying storage device and the host's I/O capabilities. But applications can achieve very high throughput by using multiple block devices in parallel and carefully tuning I/O queue depths and request sizes.
Object storage shines for throughput scaling. Since there's no global file system state to maintain, object stores can scale horizontally by adding more storage nodes. Applications can achieve petabyte-scale throughput by parallelizing requests across many objects and storage nodes.
Consistency Models
File storage provides strong consistency through POSIX semantics. When a write() call returns, subsequent read() calls from any process will see the updated data. The file system's journal ensures that metadata updates are atomic even across crashes.
Block storage provides whatever consistency model the application implements. If you're building a database on block storage, you're responsible for implementing journaling, transaction logging, and crash recovery. This complexity is why most applications use file storage or purpose-built databases rather than raw block devices.
Object storage trades consistency for scalability. Eventual consistency means that updates might not be immediately visible to all clients. Some object stores offer stronger consistency options, but these typically come with performance penalties or availability trade-offs.
Common Challenges and Debugging Strategies
I/O Performance Issues
The most common storage performance problems I encounter fall into a few categories:
File System Fragmentation: Files that grow over time can become fragmented across many non-contiguous blocks. This is especially problematic for sequential workloads like log files or database data files.
# Check fragmentation on ext4
filefrag /path/to/large/file
# Defragment (requires downtime)
e4defrag /path/to/large/fileBlock Device Queue Saturation: Applications that issue many concurrent I/O requests can saturate block device queues. Monitor queue depth and adjust application concurrency accordingly.
# Monitor block device statistics
iostat -x 1
# Check queue depth
cat /sys/block/sda/queue/nr_requestsObject Storage Rate Limiting: Cloud object storage services impose rate limits that can cause unexpected latency spikes. S3's request rate limits are per prefix, so using random prefixes can help distribute load.
Debugging Tools
strace: Shows system calls and their latency, perfect for understanding file I/O patterns.
# Trace file operations for a process
strace -e trace=file -p <pid>
# Time system calls to find slow operations
strace -T -e read,write,fsync ./my-appblktrace: Provides detailed information about block I/O operations.
# Trace block operations
blktrace -d /dev/sda -o - | blkparse -i -
# Analyze I/O patterns
btrace /dev/sdaiotop: Shows I/O usage by process, similar to top for CPU usage.
# Monitor I/O by process
iotop -o # Only show processes doing I/OApplication-Level Optimizations
Batch Operations: Both file and object storage benefit from batching small operations into larger ones. Instead of many small writes, accumulate data and write larger chunks.
Alignment: Block storage performs best when I/O operations align to device block boundaries. Most modern devices use 4KB blocks, so align your reads and writes accordingly.
// Align buffer to 4KB boundary
void *buffer;
if (posix_memalign(&buffer, 4096, size) != 0) {
// Handle alignment failure
}Parallelism: Object storage scales with parallel requests. Use multiple threads or async I/O to issue concurrent requests to different objects.
Caching Strategies: Implement application-level caching to reduce I/O operations. This is especially important for object storage where every operation has network overhead.
Choosing the Right Storage Type
The decision between object, block, and file storage depends on your specific requirements:
Use File Storage When:
You need POSIX semantics and compatibility with existing tools
Your application uses standard file operations (read, write, seek)
You want the kernel to handle caching and optimization
You're dealing with structured data that benefits from hierarchical organization
Use Block Storage When:
You need maximum performance and control over I/O
You're implementing a database or file system
You want predictable latency without cache variability
You need to optimize data layout for your specific workload
Use Object Storage When:
You need to scale to petabytes of data
Your data is mostly immutable (write-once, read-many)
You can tolerate eventual consistency
You want to eliminate infrastructure management overhead
Many modern applications use multiple storage types. A web application might store user files in object storage, use block storage for its database, and use file storage for application logs and configuration files.
The Future of Storage
Storage technology continues to evolve rapidly. NVMe storage is making block device latency approach memory latency. Object storage systems are adding stronger consistency guarantees while maintaining scalability. New file systems like ZFS and Btrfs provide features like snapshots and data integrity checking that blur the lines between storage types.
Understanding the low-level mechanisms becomes more important as these systems become more complex. Whether you're debugging performance issues, architecting new systems, or just trying to understand why your application behaves the way it does, knowledge of how storage actually works pays dividends.
The abstractions are getting better, but they're not magic. When you understand what's happening under the hood—how file descriptors interact with inodes, how block I/O flows through kernel layers, how object storage handles eventual consistency—you can build more reliable, performant systems.
Key Takeaways
Storage systems make fundamental trade-offs between consistency, performance, and scalability. File storage prioritizes POSIX compatibility and ease of use. Block storage optimizes for raw performance and application control. Object storage embraces eventual consistency to achieve massive scale.
Each storage type involves different kernel subsystems and has different performance characteristics. File I/O goes through the VFS layer and depends heavily on caching. Block I/O bypasses file system overhead but requires careful attention to alignment and scheduling. Object storage eliminates many traditional bottlenecks but introduces network latency and consistency challenges.
The choice of storage type affects not just performance, but also how you architect your application, handle errors, and debug problems. Understanding these low-level mechanisms helps you make informed decisions and troubleshoot issues when they arise.
References
Linux Kernel Documentation: Block Layer
POSIX.1-2017 Standard
Amazon S3 API Reference
"Understanding the Linux Kernel" by Daniel P. Bovet and Marco Cesati
ext4 File System Documentation
NVMe Specification 1.4
"Designing Data-Intensive Applications" by Martin Kleppmann