
The Hidden Cost: Physical Memory Requirements of Virtual Memory Systems
Unmasking the Recursive Cost: How Managing Virtual Memory Consumes Your RAM

Table of Contents
Understanding the Basics of Virtual Memory
Page Tables: The Translation Mechanism
The Problem Scales with Address Space
Multi-level Page Tables: A Memory-Saving Solution
Working Through a Memory Example
Real-World Memory Usage Patterns
64-bit Systems: Even More Levels
The TLB: Making Address Translation Fast
Memory Overhead in Practice
Practical Implications for Memory-Intensive Applications
Case Study: Memory Analysis in Reverse Engineering
Exercises for Practice
Final Thoughts
Virtual memory is one of those fundamental computer concepts that seems deceptively simple at first glance. "It's just a way to make the computer think it has more memory than it actually does," you might say. But think a little deeper, and you'll find a complex system with fascinating tradeoffs that impact everything from application performance to overall system stability.
What often gets overlooked is the fact that virtual memory itself consumes physical memory. It's a bit like those storage containers meant to save space—they help organize things efficiently, but you still need somewhere to put the containers themselves. The same applies to virtual memory: the structures needed to manage it take up precious physical memory.
Let's explore how much physical memory virtual memory actually requires, and why understanding this matters for performance optimization, debugging, and reverse engineering.
Understanding the Basics of Virtual Memory
Before diving into the memory requirements, let's establish what virtual memory is and why we need it.
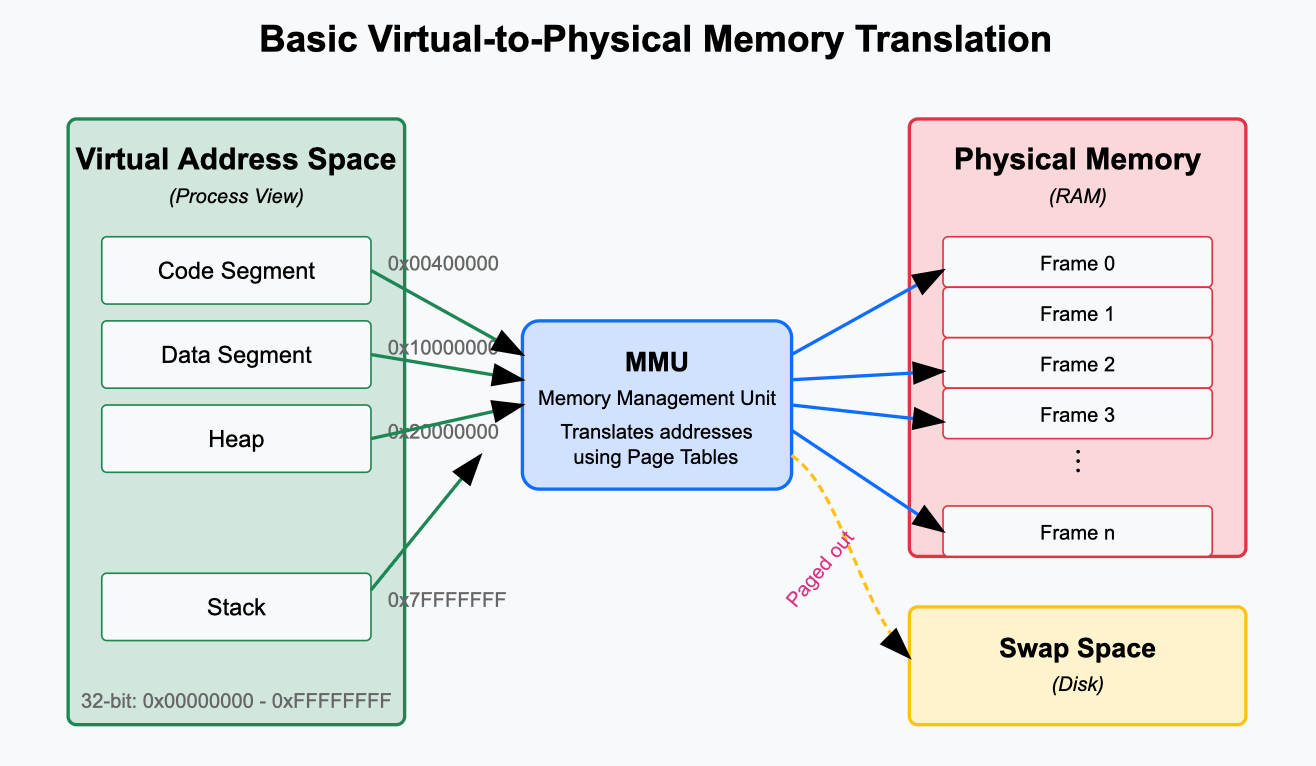
Virtual memory creates an abstraction layer between the memory addresses programs use (virtual addresses) and the actual physical memory locations in RAM (physical addresses). This abstraction serves several crucial purposes:
It isolates processes from each other, preventing one program from accessing another's memory
It allows programs to operate as if they have access to a continuous block of memory, even if physical memory is fragmented
It enables the system to use disk space as an extension of RAM when physical memory is limited
The magic behind this abstraction is a mechanism called "paging," where memory is divided into fixed-size chunks called pages (typically 4KB in size). When a program accesses memory using a virtual address, that address must be translated to a physical address—and that's where page tables come in.
Page Tables: The Translation Mechanism
Page tables are the core component that makes virtual memory work. They act as translation directories that map virtual page numbers to physical frame numbers. Every time a program accesses memory, the system uses these tables to convert the virtual address to a physical one.
The simplest implementation of a page table is a linear (or flat) structure. In this approach, each virtual page within a program's address space has a corresponding entry in the page table, regardless of whether that page is actually used or not.
Let's consider what this means in terms of memory usage. In a 32-bit system with a 4GB virtual address space and 4KB pages:
4GB address space ÷ 4KB page size = 1,048,576 pages
Each page table entry typically requires 4 bytes
Total memory for one process's page table: 4MB
That might not sound too bad for a single process, but multiply it by dozens or hundreds of processes running simultaneously, and you're looking at hundreds of megabytes of memory dedicated solely to page tables.
For instance, with just 50 concurrent processes:
50 processes × 4MB per page table = 200MB
That's 200MB of physical memory consumed just for managing virtual memory—memory that could otherwise be used for actual program data and code.
The Problem Scales with Address Space
As computer architecture evolved from 32-bit to 64-bit systems, the problem became exponentially worse. A 64-bit address space is vastly larger than 32-bit:
32-bit address space: 2^32 bytes = 4GB
64-bit address space: 2^64 bytes = 16 exabytes (that's 16 billion gigabytes)
If we were to use the same linear page table approach for a 64-bit system, the memory requirements would be astronomical. Even though no current system uses the full 64-bit address space (most implement 48-bit or 52-bit addressing), the potential size of these virtual address spaces makes linear page tables completely impractical.
Multi-level Page Tables: A Memory-Saving Solution
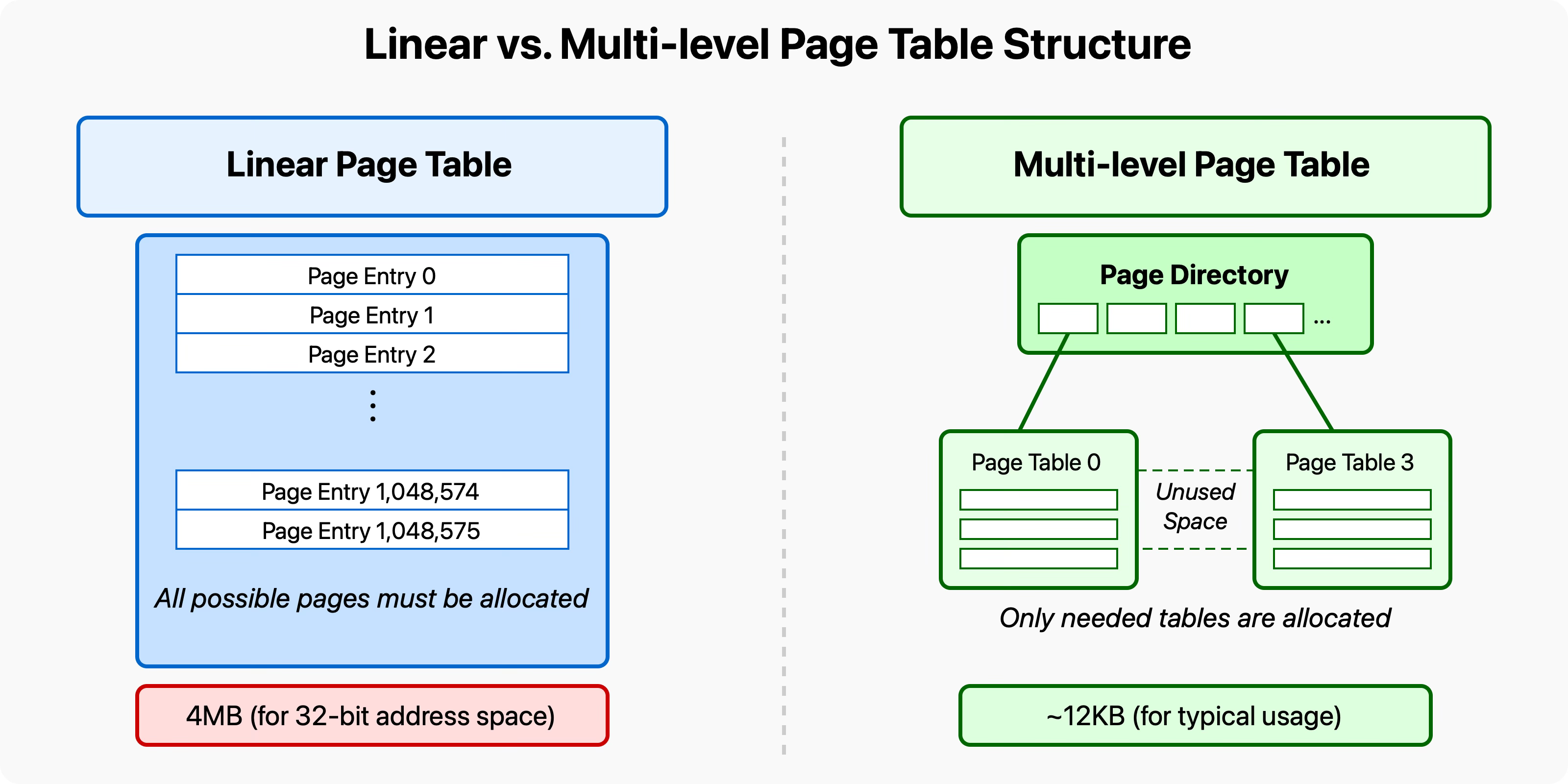
To address this challenge, modern systems implement multi-level (or hierarchical) page tables. Instead of one massive table, the system uses a hierarchy of smaller tables organized in levels.
The key insight that makes multi-level page tables efficient is that most programs use only a tiny fraction of their potential virtual address space. Large portions of the address space remain unused, and with multi-level paging, we don't need to allocate memory for page tables covering those unused regions.
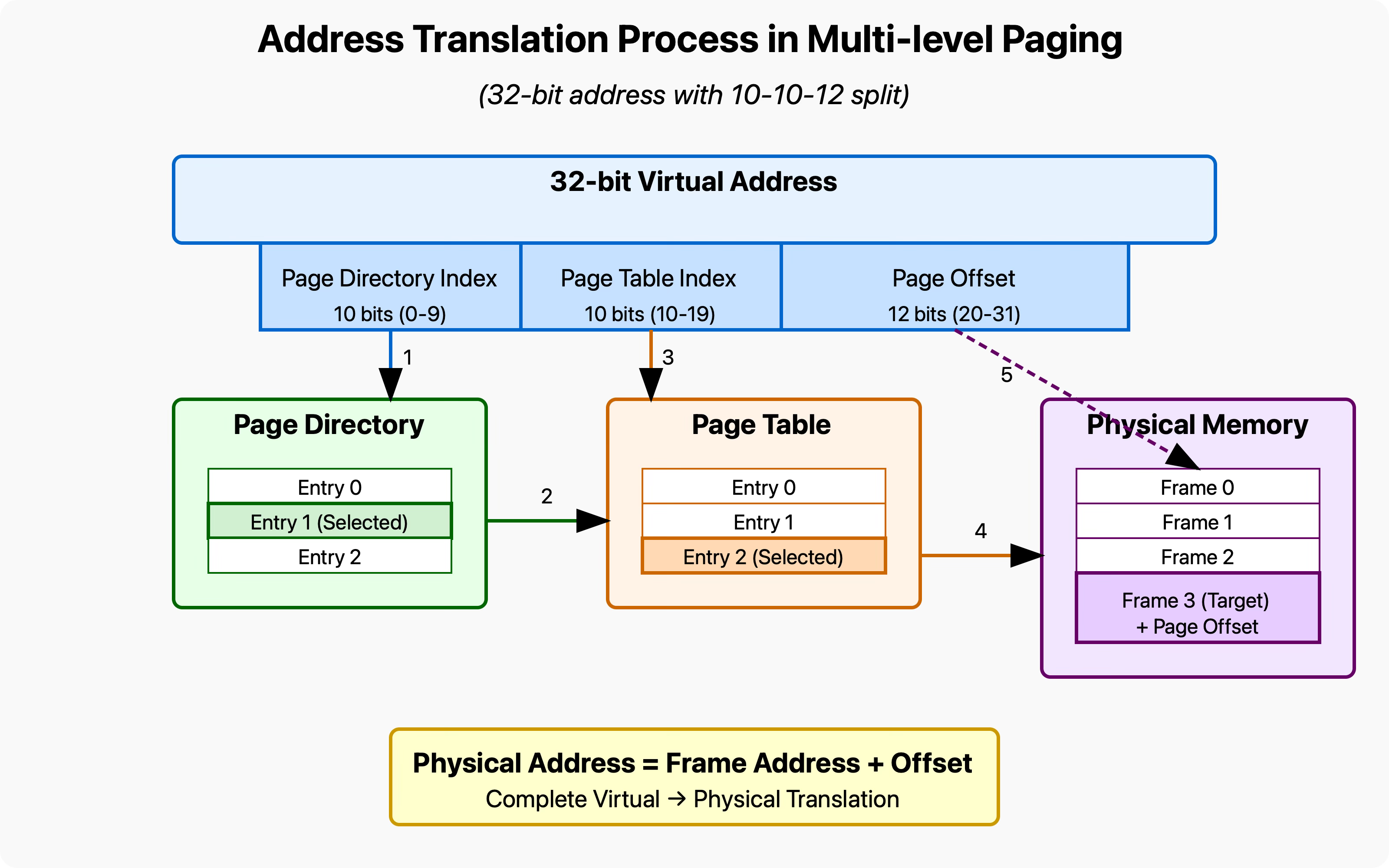
Here's how it works: The virtual address is broken down into segments. Each segment is used as an index into a different level of the page table hierarchy:
Virtual Address (32-bit example with 2-level paging):
[10 bits: L1 index][10 bits: L2 index][12 bits: page offset]When translating an address, the system:
Uses the first 10 bits to index into the top-level page directory
The entry either points to a second-level page table or indicates the region is unused
If valid, the next 10 bits index into the second-level table to find the physical frame
The final 12 bits (for 4KB pages) provide the offset within that physical frame
The critical memory-saving feature is that second-level page tables are only created for parts of the address space that are actually used. If a program never touches a particular region of its address space, no second-level table needs to be allocated for that region.
Working Through a Memory Example
Let's make this concrete with a typical example from a 32-bit system using 2-level paging:
Each process has a 4GB (2^32 bytes) virtual address space
The system uses 4KB (2^12 bytes) pages
First-level page directory has 1024 (2^10) entries
Second-level page tables also have 1024 (2^10) entries
Each page table entry is 4 bytes
Memory requirements:
First-level page directory: 1024 entries × 4 bytes = 4KB (always required)
Each second-level page table: 1024 entries × 4 bytes = 4KB (only created when needed)
If a program uses memory sparsely—let's say just 8MB of memory spread across different regions of its address space—it might need only 2-3 second-level page tables. That would mean:
First-level directory: 4KB
2-3 second-level tables: 8-12KB
Total: 12-16KB (compared to 4MB for a linear table)
That's a massive reduction—from 4MB down to around 16KB, or approximately 0.4% of the original size!
Real-World Memory Usage Patterns
In practice, most programs don't use memory randomly. They tend to allocate memory in somewhat contiguous chunks, which further improves the efficiency of multi-level page tables. Common memory regions include:
Program code (text segment)
Global variables (data segment)
Heap (dynamically allocated memory)
Stack (function call frames, local variables)
These regions might occupy just a handful of second-level page tables, even for moderately sized programs. The stack and heap can grow as needed, but they typically start small and expand gradually.
Consider a typical program using:
2MB for code
1MB for global data
5MB for heap
2MB for stack
Even with some fragmentation, this might require only 5-10 second-level page tables, for a total page table overhead of 24-44KB.
64-bit Systems: Even More Levels
For 64-bit systems, two levels aren't enough. Modern 64-bit architectures typically implement 4 or even 5 levels of page tables. Each level further divides the address space, allowing for extremely sparse memory usage patterns without excessive overhead.
A typical 4-level paging scheme on x86-64 might divide a 48-bit virtual address like this:
[9 bits: L1 index]
[9 bits: L2 index]
[9 bits: L3 index]
[9 bits: L4 index]
[12 bits: offset]With each page table containing 512 entries (2^9), the worst-case scenario (if every possible page was used) would require enormous amounts of memory. But in practice, the ability to allocate page tables on-demand means the actual overhead remains manageable.
For a program using 100MB of memory scattered throughout its address space, the page table overhead might be around 1-2MB—still significant, but far less than would be required with linear page tables.
The TLB: Making Address Translation Fast
There's another important aspect to consider: performance. Looking up an address through multiple levels of page tables would be painfully slow if done for every memory access. Each level requires a separate memory access, potentially adding 3-5 memory reads before even accessing the actual data!
This is where the Translation Lookaside Buffer (TLB) comes in. The TLB is a special hardware cache that stores recently used page table entries. When a program accesses memory, the processor first checks the TLB. If the translation is found (a TLB hit), the physical address is available immediately without having to walk the page table hierarchy.
Modern processors typically have multi-level TLBs:
L1 TLB: Very small (64-128 entries) but extremely fast
L2 TLB: Larger (512-1536 entries) but slightly slower
The TLB dramatically reduces the performance penalty of virtual memory translation. In well-tuned systems, TLB hit rates can exceed 99%, meaning only a tiny fraction of memory accesses require the full page table walk.
Memory Overhead in Practice
When analyzing memory usage in real systems, the overhead of page tables is not immediately obvious. Tools like top or Task Manager show memory allocated to processes but don't separate out how much is used for the page tables themselves.
On Linux, you can get some insight with the /proc/meminfo file, which includes entries like:
PageTables: 124876 kBThis shows the total memory used for page tables across all processes. To examine a specific process, tools like pmap can help:
$ pmap -x <pid> | grep total
total 524288KHowever, this doesn't break down how much of that total is page table overhead versus actual program data.
For more detailed analysis, specialized tools like perf can provide insights into TLB misses and page table walks, which indirectly indicate the complexity of a process's page tables:
$ perf stat -e dTLB-load-misses program_namePractical Implications for Memory-Intensive Applications
Understanding page table overhead has several practical implications:
Memory fragmentation impacts page table size: Programs that allocate memory in widely scattered locations force the creation of more page tables.
Large sparse data structures can be costly: Data structures like huge hash tables with low occupancy might seem memory-efficient but can require disproportionate page table overhead.
Huge pages can reduce overhead: Many systems support "huge pages" (typically 2MB or 1GB instead of 4KB), which reduce the number of page table entries needed for contiguous memory regions.
For example, running a database with 10GB of buffer pool using 4KB pages requires millions of page table entries. Switching to 2MB huge pages could reduce the number of entries by a factor of 512, significantly reducing page table overhead.
Let's see how to enable huge pages on Linux:
# Check available huge page sizes
$ cat /proc/meminfo | grep Huge
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
# Allocate 100 huge pages
$ sudo sysctl -w vm.nr_hugepages=100
# Applications can use huge pages with mmap() and the MAP_HUGETLB flagCase Study: Memory Analysis in Reverse Engineering
Page tables become particularly interesting in reverse engineering and memory forensics. When analyzing memory dumps, understanding the relationship between virtual and physical addresses is crucial.
For instance, when using a tool like Volatility to analyze a memory dump:
$ volatility -f memory.dmp --profile=Win10x64 vadinfo -p 1234This command shows the virtual address descriptors (VADs) for process ID 1234, revealing how virtual memory is laid out and which regions are backed by physical memory versus being paged out.
The translation from virtual to physical addresses follows the same multi-level page table structure we've discussed. Memory forensics tools must essentially recreate the MMU's translation process to map virtual addresses in the process to physical locations in the memory dump.
Exercises for Practice
Monitor Page Table Size: On a Linux system, watch how page table memory changes as you start and stop applications:
watch -n 1 'grep PageTables /proc/meminfo'Compare Process Memory Maps: Run a memory-intensive application (like a browser) and use
pmapto analyze its memory usage patterns:
pmap -x $(pidof firefox) | lessExperiment with Huge Pages: Modify a simple program to allocate memory with and without huge pages, and compare the performance and memory overhead.
Analyze TLB Pressure: Use performance counters to measure TLB misses for different memory access patterns:
perf stat -e dTLB-load-misses,dTLB-store-misses ./your_programFinal Thoughts
The physical memory required by virtual memory systems isn't fixed—it's a function of how programs use their address space. Well-designed systems and applications can minimize this overhead through techniques like:
Using huge pages for large contiguous allocations
Keeping related data together to improve locality
Being mindful of memory fragmentation
Limiting the number of concurrent processes
Modern operating systems have evolved sophisticated memory management techniques that make virtual memory practical despite its overhead. The benefits of process isolation, memory protection, and the ability to use more memory than physically available usually outweigh the costs.
Understanding these tradeoffs helps us write more efficient code and build more responsive systems. Next time you're debugging a memory issue or optimizing a memory-intensive application, remember that there's more to memory usage than meets the eye—the structures managing your virtual memory are consuming physical memory too.
The virtual memory system is a perfect example of how clever computer science solutions often involve trading one resource for another—in this case, using some memory to manage the rest more efficiently. It's these kinds of tradeoffs that make systems programming both challenging and fascinating.
Great post, I was just computing how much space is needed to allocate 100MB on 64 bit. In the post it is said to be 1-2 MB. However, to me it seems a bit lower.
To simplify let's consider the space required to allocate 128MB: (2^7)*(2^20) Bytes.
With pages of size 4096 Bytes (2^12 Bytes), we need to allocate: (2^7)*(2^20)/(2^12) Pages.
That is 2^15 Pages.
Since, each L1 table can refer to 2^9 Pages, we need at least (2^15)/(2^9)=2^6 full L1 Tables.
This occupies (2^6)*(2^9)*8 Bytes = 2^18 Bytes
Then we need to add 2^6 L2 entries to refer to the L1 tables.
This occupies 2^6*8 Bytes = 2^9 Bytes
Overall we need 2^18+2^9 Bytes, that is 256KB+512Bytes.
Are my computations correct or am I missing something?.
Thank you very much.